
[인공지능] AI 모델의 검증 기준과 검증 방법

포스팅된 글의 인용한 모든 이미지는 CCL 라이선스의 이미지만을 사용했으며, 출처를 밝힙니다.
AI 모델의 검증 방법
데이터셋은 모델을 훈련하고 평가하는 데 사용되는 데이터의 집합
- 데이터셋을 Traning Set / Validation Set / Test Set으로 데이터를 나눔
- Traning Set : AI 모델을 훈련, 60%
- Validation Set : 훈련이 끝난 모델의 성능 검증, 20%
- Test Set : 최종 출시 전 AI 모델 성능 검증, 20%
훈련 세트 (Training Set, 60%):
이 부분은 실제로 모델을 훈련하는 데 사용되는 데이터. 모델은 이 데이터를 사용하여 패턴과 관계를 학습하며, 최적의 파라미터를 찾아가는 과정을 거친다.
검증 세트 (Validation Set, 20%):
모델이 훈련되면 훈련 데이터에 대한 성능은 점차 개선된다. 하지만 모델이 훈련 데이터에 너무 맞춰져 다른 데이터에 대한 일반화 능력을 잃는 Overfitting을 방지하기 위해 사용된다. 검증 세트는 모델의 성능을 지속적으로 평가하고, 하이퍼파라미터 조정과 같은 모델 튜닝을 위해 사용된다.
테스트 세트 (Test Set, 20%):
최종 모델의 실제 성능을 평가하기 위해 사용된다. 모델의 일반화 능력을 평가하는 데 사용된다. 모델이 실제 환경에서 얼마나 잘 수행되는지 확인할 수 있다.
데이터셋을 훈련, 검증 및 테스트 세트로 나누는 이유는 모델의 성능 평가를 공정하게 하기 위함이다.
- 훈련 데이터로 모델을 훈련시킨다.
- 검증 데이터로 모델의 일반화 능력과 하이퍼파라미터를 조정하여 Overfitting을 회피한다.
- 테스트 데이터로 최종 모델의 성능을 평가하여 실제 환경에서의 예측 능력을 확인한다.
AI 모델의 검증 기준
1. 데이터 편향 (Underfitting)
데이터 편향은 모델이 주어진 데이터를 충분히 학습하지 못해 훈련 데이터와 검증 데이터 모두에서 낮은 성능을 보이는 상황
모델의 복잡도 < 문제의 복잡도
모델이 문제에 비해 너무 단순함. 모델이 데이터의 다양한 패턴과 관계를 학습하지 못하고 예측이 부족
모델을 더 복잡하게 만들거나, 더 많은 특성을 추가하거나, 학습 반복 횟수를 늘리는 등의 방법을 사용하여 데이터 편향을 해결
2. 데이터 분산 (Overfitting)
데이터 분산은 모델이 훈련 데이터에 지나치게 맞춰져 있어 검증 데이터에서는 좋은 성능을 보이지만, 새로운 데이터에 대해서는 일반화 능력이 떨어지는 상황
모델의 복잡도 > 문제의 복잡도
모델이 훈련 데이터에 너무 맞춰져 있어 실제 문제보다 더 복잡한 모델을 생성하는 것이 문제이다.
모델의 복잡도 감소, 데이터 추가를 시켜야 함. 모델의 복잡도를 감소시키거나, Regularization를 통해일반화 능력을 높이거나, 더 많은 다양한 데이터를 추가하여 데이터 분산을 완화해야 한다.
정규화
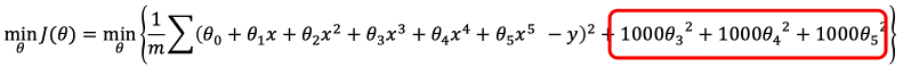
- Underfitting(편향)과 Overfitting(분산)을 회피하기 위한 모델 개선 방법
- 복잡한 모델을 세운 후, 오버피팅이 발생할 때 마다 항이 높은 차수부터 하나씩 무력화한다.
- Loss 함수에 θ에 높은 계수를 곱해서 포함시켜 높은 차수부터 하나씩 무력화 하는 방식
'Data Science > 머신러닝 & 딥러닝' 카테고리의 다른 글
| [머신러닝] 비지도 학습 : 군집화(Clustering) (0) | 2023.08.28 |
|---|---|
| [머신러닝] 지도 학습 : 분류(Classification)와 모델 평가 (0) | 2023.08.28 |
| [머신러닝] 지도 학습 : 다변량 회귀와 경사하강법 최적화 방법(Optimizer) (0) | 2023.05.03 |
| [인공지능] AI 개요와 라이프사이클 (0) | 2023.05.03 |
| [머신러닝] - 지도 학습 : 방법론과 단순 선형 회귀 구현 (0) | 2023.03.25 |








