
[인공지능] AI 개요와 라이프사이클

인공지능의 역사
1st Spring of AI (1950~1970)
- 지식 표현, 추론(기존 지식-> 새로운 지식), 게임 트리(인공지능도 유희를 가질 수 있는가?)
- 강한 인공지능을 추구 -> 기대만큼의 성과를 거두지 못하여 1st Winter
2nd Spring of AI (1980~1990)
- 약한 인공지능을 추구
- 추론 -> 전문가 시스템
- 퍼셉트론 -> MLP, Backpropagation
- 기대만큼의 성과를 거두지 못하여 2nd Winter
3rd Spring of AI (2010 ~)
- 배경 : 충분한 데이터, 발전하는 컴퓨팅 파워, 새로운 기술(심층학습 등..)
- 약한 인공지능을 추구 + 다양한 분야의 문제를 사람만큼 잘 해결하는 인공지능
- 시각 지능, 언어 지능, 데이터 지능 등..
인공지능 개요
1. 강한 인공지능 vs 약한 인공지능
2. 상징주의 vs 연결주의
- 상징주의 : 알고리즘을 매우 연구하여 문제해결 -> 초반 반짝
* 명확한 표현과 절차를 중요시 함 -> 정의하기 힘듦
* (상징주의 + 강한 인공지능) : 지식 표현, 추론, 탐색
* (상징주의 + 약한 인공지능) : 전문가 시스템
- 연결주의 : 학습을 통한 인공지능 솔루션 추구
* 학습이 중요 -> 데이터가 중요
* 데이터 확보의 어려움과 학습에 많은 시간이 걸림
-> 컴퓨팅 자원과 기술의 발전으로 시간이 지나면 문제 해결
* (연결주의 + 약한 인공지능) : 기계학습, 심층학습 등..
컴퓨팅 자원
1. GPU의 발전
- CPU(~2010) -> GPU(2010~) -> NPU(2020~)
- 1980 : VGA로 시작
- 1990~2000 : 자체적 메모리와 연산 장치를 갖추어 CPU의 부담을 낮추며, 병렬 처리 기능이 탑재됨
- 2010 ~ : 병렬 처리 기능을 AI 모델 훈련에 활용하게 됨
- 클라우드 서비스의 등장으로 일반인들도 고가의 GPU를 사용하게 됨
2. GPU의 장점
- 병렬 처리 능력, 저렴한 비용과 고성능 연산, 확장성(클라우드, 분산 시스템..)
3. NPU
- 회사마다 자사의 데이터 형태에 최적화된 Processing Unit을 개발
- 애플의 M1 Process
# AI 라이프사이클
기획 -> 데이터 준비 -> AI 모델 개발 -> 배포 -> 기획…
인공지능?
인공지능 = 데이터 + 모델 + (컴퓨팅 자원)
모델 = 코드 + 파라미터
- Y = ax + b : 모델
- a, b : 파라미터
- x, y: 데이터
데이터
- 변수들의 질적/양적 속성을 나타내는 정보의 집합
- 개수(행, M), 속성(열, N)의 tensor -> 데이터의 개수 : MxN
- 정보 -> (객관화, 체계화) -> 데이터 -> (분석) -> 정보
- 정형 데이터 : 속성을 명확하게 정의할 수 있음
- 비정형 데이터 : 속성을 명확하게 정의할 수 없음(영상, 음성, 문장..)
- 혼합형 데이터 : 정형+비정형의 성질을 모두 가짐(사진 + exif(메타데이터->구조화됨)
1. 데이터 준비
1. 데이터 확보 : 웹 크롤링, API 활용, 공개 데이터셋 활용, 직접 수집 등..
2. 데이터 정제
- 목적과 상관없는 필요 없는 속성 삭제
- 이상 원소(outlier) 삭제 -> 마이클 조던
- 결측값 처리 : 일부 변수 값이 누락되어 있는 상태
3. 특징 추출
- 데이터의 속성 중 의사 판단에 큰 영향을 미치는 속성
- Implict feature extraction : 학습 과정에서 특징을 자동으로 추출하는 방법, 비정형 데이터에 해당하는 경우가 많음
2. ML 모델 준비
- ML 모델 설계 -> 훈련 -> 평가
목적에 따른 ML모델 분류
- 분류/인식 : 데이터가 어떤 카테고리(Label)에 속하는지 판단. 범주형 변수를 인식하고 구분하는 기법. 데이터를 잘 구분하는 경계를 찾는 문제.
- 회귀 : 데이터로부터 연속형 변수(특정 값)을 예측. 데이터를 잘 표현하는 수식을 찾는 문제
- 군집화 : 데이터의 유사 집단을 파악. 범주형 값이 됨
- 위 세가지 모두 정형 데이터/비정형 데이터 모두 처리 가능
훈련 데이터에 따른 ML모델 분류
- 지도 학습 : 훈련 데이터에 Label이 있음. Label을 예측하도록 훈련
- 비지도 학습 : 훈련 데이터에 Label이 없음, 특징을 추출하여 유사집단을 찾을 수 있도록 훈련
- 강화 학습 : Action에 따른 Reward를 예측하게 함
분류는 여러 데이터들을 각각의 범주로 구분하는 [경계]를 찾는 문제로 이해할 수 있고, 회귀는 여러 데이터들을 가장 잘 표현하는 [수식(함수)]을 찾는 문제로 이해할 수 있다.
ML 모델 결정하기
1. 입력과 출력 : (x1, x2) -> (y)
* 입력이 하나 -> 단변량
* 입력이 여러개 -> 다변량
2. 모델의 종류 : 분류 vs 회귀 vs 군집화
3. 모델의 복잡도 : 선형 < 다항 < 로지스틱 < ???
3. ML 모델 훈련
- 손실 함수 설정
- 최적화(경사하강법) 수행
4. 결과 분석
- 가시화
- 평가
AI 모델의 검증 방법
- 데이터셋을 Traning Set / Validation Set / Test Set으로 데이터를 나눔
- Traning Set : AI 모델을 훈련, 60%
- Validation Set : 훈련이 끝난 모델의 성능 검증, 20%
- Test Set : 최종 출시 전 AI 모델 성능 검증, 20%
AI 모델의 검증 기준
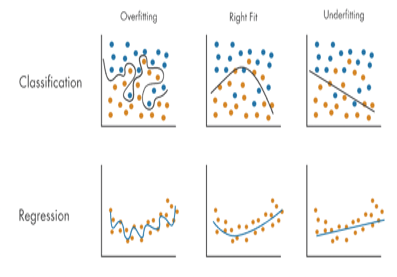
편향 (Bias)과 분산 (Variance)
Underfitting
- 데이터 편향이 클 때 주로 발생
- 모델의 복잡도 < 문제의 복잡도
- 모델이 문제에 비해 너무 단순함
- 모델의 복잡도를 향상시켜야 함
Overfitting
- 데이터 분산이 클 때 주로 발생
- 모델의 복잡도 > 문제의 복잡도
- 모댈의 복잡도 감소, 데이터 추가를 시켜야 함
'Data Science > 머신러닝 & 딥러닝' 카테고리의 다른 글
| [머신러닝] 비지도 학습 : 군집화(Clustering) (0) | 2023.08.28 |
|---|---|
| [머신러닝] 지도 학습 : 분류(Classification)와 모델 평가 (0) | 2023.08.28 |
| [인공지능] AI 모델의 검증 기준과 검증 방법 (1) | 2023.08.28 |
| [머신러닝] 지도 학습 : 다변량 회귀와 경사하강법 최적화 방법(Optimizer) (0) | 2023.05.03 |
| [머신러닝] - 지도 학습 : 방법론과 단순 선형 회귀 구현 (0) | 2023.03.25 |








