

[머신러닝] 앙상블 모델 : Voting / Bagging / Random Forest 적용해보기

포스팅된 글의 인용한 모든 이미지는 CCL 라이선스의 이미지만을 사용했으며, 출처를 밝힙니다.
앙상블 모델
앙상블 모델은 여러 다른 개별 모델을 결합하여 예측 능력을 향상시키는 기법이다.
서로 다른 알고리즘, 다른 훈련 데이터셋을 이용할 수 있으며, 모델들의 예측을 통합하여 미지의 데이터로부터의 예측을 수행한다.
Voting
각 모델의 결과에 대한 투표를 실시하는 것.
Voting은 여러 다른 모델의 예측 결과를 결합하여 최종 예측을 수행하는 앙상블 기법이다.
각 모델의 예측을 조합하여 더 강력한 예측을 만들어낸다.
Hard Voting
다수결 방식으로 예측 결과를 합치는 방법.
각 모델이 예측한 클래스 레이블 중 가장 많은 클래스 레이블을 최종 예측 결과로 선택한다. 이 방식은 각 모델이 동일한 중요도를 가진 경우에 사용된다.
Soft Voting
각 모델의 예측 결과에 대한 확률의 평균을 계산하여 최종 예측을 수행한다.
모델마다 클래스에 대한 확률을 예측하고, 이 확률을 평균하여 가장 높은 평균 확률을 가진 클래스를 최종 예측 결과로 선택한다.
신뢰도를 고려하므로, 예측 확률 정보가 있는 경우에 효과적이다.
Bagging
Bagging (Bootstrap Aggregation)
여러 개의 모델을 동시에 학습시켜 예측을 결합하는 방법.
주로 분류 및 회귀 문제에 사용되며, Overfitting을 줄이고 모델의 일반화 성능을 향상시키는데 도움을 준다. Bagging은 아래의 두 가지 단계를 거친다.
1. Bootstrap (샘플링 과정)
복원 추출을 통해 원본 데이터셋으로부터 여러 개의 부분 데이터셋을 생성, 즉 샘플링 과정을 거친다.
각 부분 데이터셋은 중복된 샘플이 포함될 수 있다.
여러 개의 데이터셋을 통해서 모델이 다양한 특성을 학습할 수 있게 된다.
2. Aggregation (통합 과정)
각 부분 데이터셋에 대해 예측 결과를 집계하여 최종 예측을 생성한다.
병렬적인 앙상블 모델의 특징을 가지게 하며, Aggression은 분류 문제에서는 Voting , 회귀 문제에서는 Averageing를 주로 사용한다. Aggregation을 통해 다양한 모델의 예측 결과를 조합함으로써 모델의 분산을 줄이고 일반화 능력을 향상시킬 수 있다.
OOB(Out-of-bagging)
Bootstrap에 포함되지 않은 데이터를 이용하여 최종 모델 성능 검증
샘플링 횟수를 늘려도 모집단의 37%는 Bootstrap에 포함되지 않음
Random Forest
Random Forest는 Bagging의 일종으로, 여러 개의 의사결정트리를 활용하여 예측 결과를 집계하는 앙상블 기법.
의사결정트리는 Overfitting이 발생할 가능성이 높으므로, 어려개의 Decision Tree을 이용하여 예측 후 통합하여 최종 예측을 생성
선형 회귀 + Manual Bagging : 직접 작성
데이터 수집 및 특징 추출
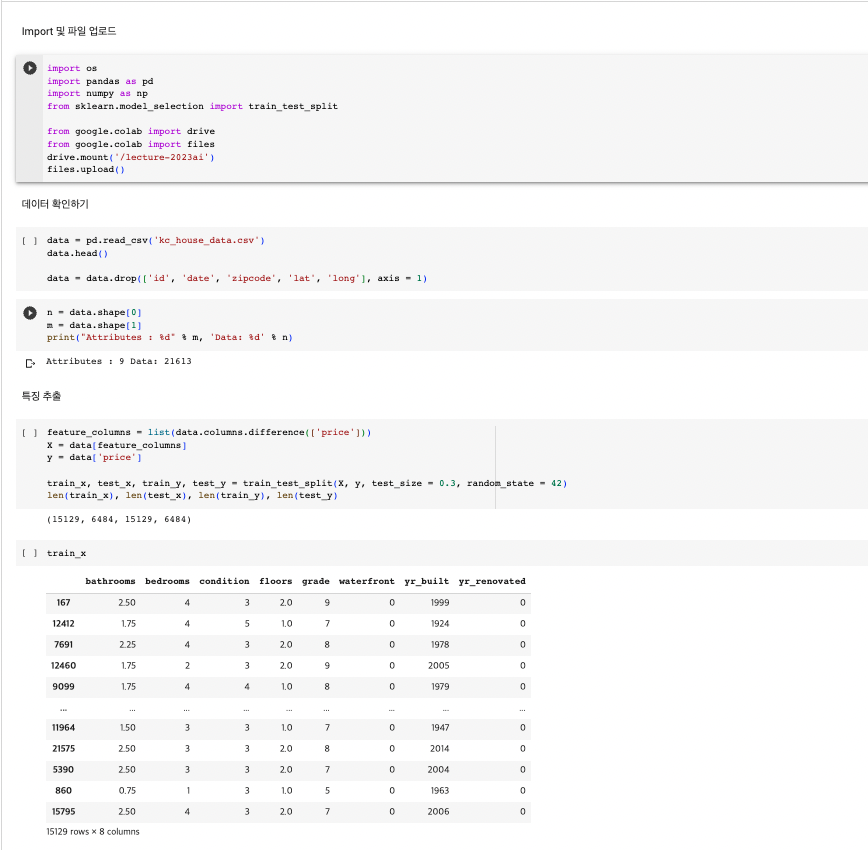
N번의 Sampling 및 선형 회귀

Bootstraping에 포함되지 않은 데이터로 검증
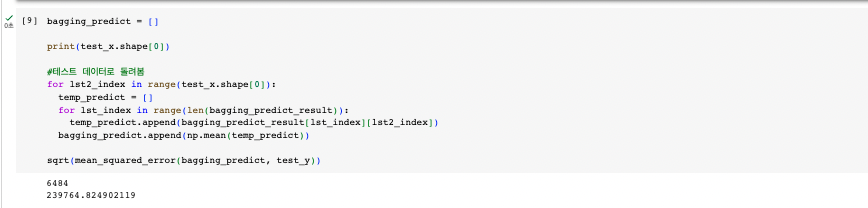
Random Forest : 직접 작성
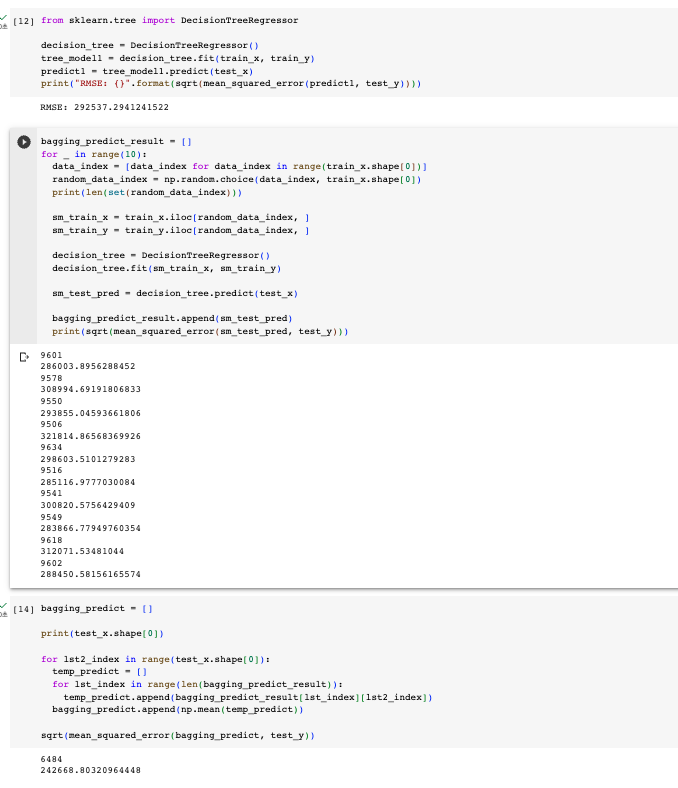
선형 회귀 + Manual Bagging : Scikit-Learn 사용

'Data Science > 머신러닝 & 딥러닝' 카테고리의 다른 글
| [딥러닝] 심층학습 시작 : 인공 신경망과 MLP (+ 신경망 모델 만들어보기) (1) | 2024.06.08 |
|---|---|
| [머신러닝] 앙상블 모델 : Boosting / Stacking 적용해보기 (0) | 2023.08.30 |
| [머신러닝] 비지도 학습 : 연관 규칙 분석 / 차원 축소 (0) | 2023.08.30 |
| [머신러닝] 비지도 학습 : K-Means Clustering (Iris dataset 군집화) (0) | 2023.08.28 |
| [머신러닝] 비지도 학습 : 군집화(Clustering) (0) | 2023.08.28 |








