

[Pandas] 데이터 분석을 위한 판다스 사용법 - 6. 데이터 편집
2023. 7. 6. 02:35
반응형
Pandas
파이썬에서 데이터 분석에 많이 이용함, 3가지 형태의 자료 구조와 연산 지원
연산
- 데이터 선택
- 데이터 가공
- 데이터 분석
- 데이터 편집
데이터 편집
자료의 구조를 제어하는 연산
- Concat
- Merge
- Join
1. Concat
자료구조를 연결하는 연산
df1 = pd.DataFrame(
{
"A": ['a00', 'a01', 'a02'],
"B": ['b00', 'b01', 'b02'],
"C": ['c00', 'c01', 'c02']
}
)
df1df2 = pd.DataFrame(
{
"B": ['B00', 'B01', 'B02'],
"C": ['C00', 'C01', 'C02'],
"D": ['D00', 'D01', 'D02']
}
)
df2
pd.concat([df1, df2])
pd.concat([df2, df1])
Axis와 Join 유형 설정하기
- inner join(교집합), outer join(합집합), left join, right join
- pd.concat([df1, df2], axis=0, join="inner") #행으로 inner join(행의 교집합)
- pd.concat([df1, df2], axis=1, join="outer") #열로 outer join(열의 합집합)
pd.concat([df1, df2], axis=0, join="inner") #행으로 inner join(행의 교집합)
pd.concat([df1, df2], axis=1, join="inner") #열로 inner join(열의 교집합)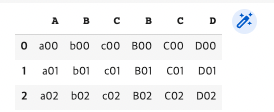
pd.concat([df1, df2], axis=0, join="outer") #행으로 outer join(행의 합집합)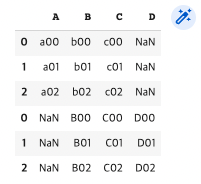
pd.concat([df1, df2], axis=1, join="outer") #열로 outer join(열의 합집합)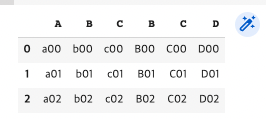
2. Merge
Key(기준 컬럼)을 기준으로 결합
df1 = pd.DataFrame({
"key": ["k0", "k1", "k2", "k3"],
"A": ["a00", "a01", "a02", "a03"],
"B": ["a10", "a11", "a12", "a13"],
})
df1df2 = pd.DataFrame({
"key": ["k0", "k1", "k2", "k3"],
"C": ["b00", "b01", "b02", "b03"],
"D": ["b10", "b11", "b12", "b13"],
})
df2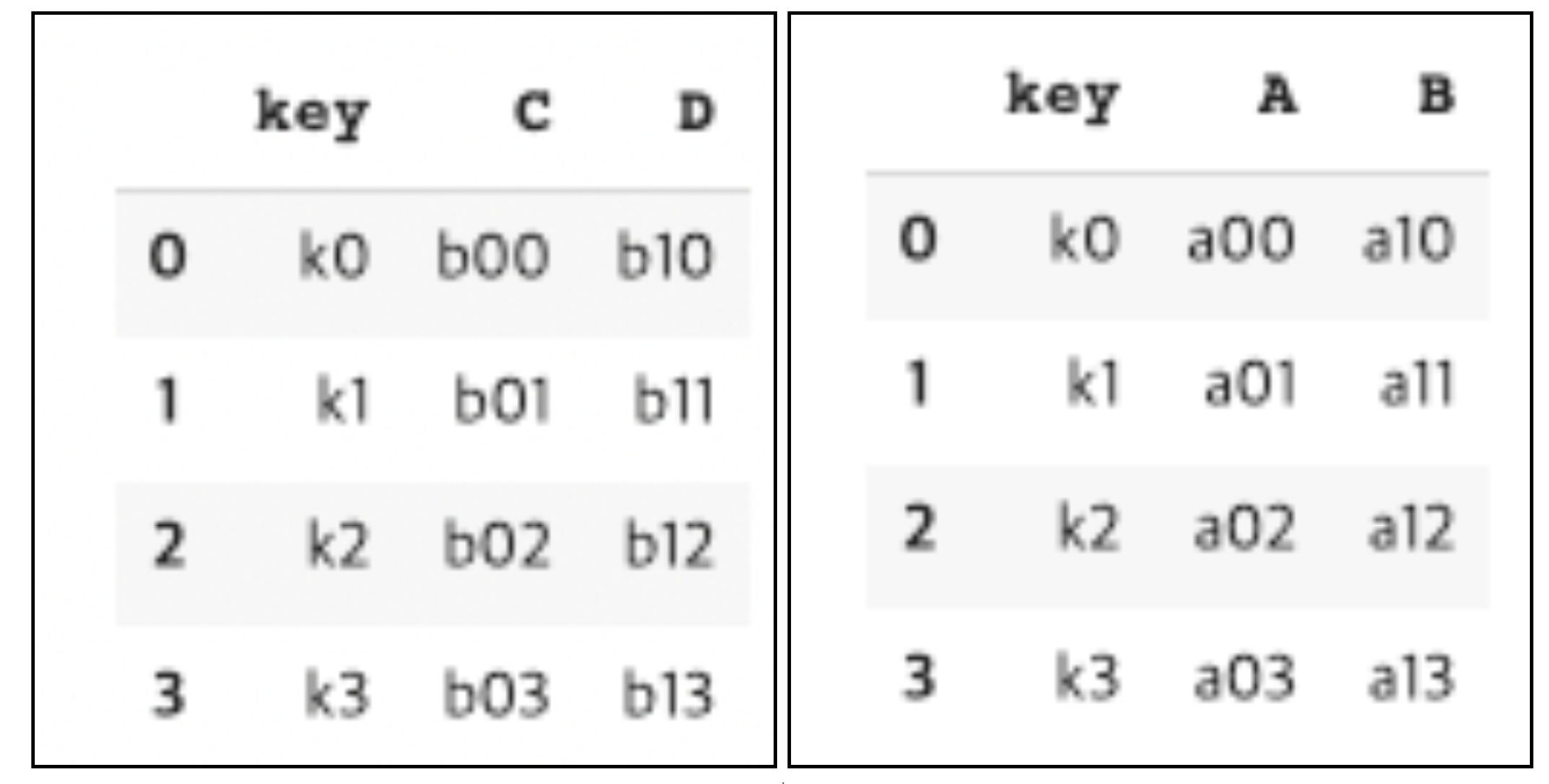
pd.merge(df1, df2, on="key")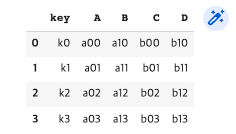
pd.merge(df2, df1, on="key")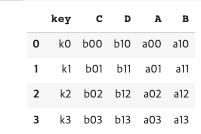
df3 = pd.DataFrame({
"key1": ["k0", "k1", "k2", "k3"],
"key2": ["k1", "k2", "k3", "k3"],
"A": ["a00", "a01", "a02", "a03"],
"B": ["a10", "a11", "a12", "a13"],
})
df3df4 = pd.DataFrame({
"key1": ["k0", "k1", "k1", "k3"],
"key2": ["k1", "k2", "k2", "k4"],
"A": ["b00", "b01", "b02", "b03"],
"B": ["b10", "b11", "b12", "b13"],
})
df4
pd.merge(df3, df4, on="key1") #교집합에 대한 Key값이 결합함 (key1 -> k0, k1, k3)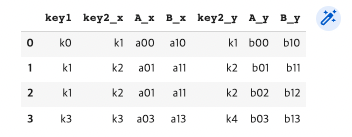
pd.merge(df3, df4, on="key2") #교집합에 대한 Key값이 결합함 (key2 -> k1, k2)
pd.merge(df3, df4, on=["key1", "key2"]) #교집합에 대한 Key값이 결합함 (key1과 key2의 그룹)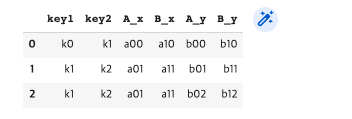
pd.merge(df3, df4, how="left", on=["key1", "key2"]) #df3 key기준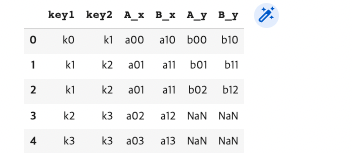
pd.merge(df3, df4, how="right", on=["key1", "key2"]) #df4 key기준
3. Join
자료구조를 연결하는 함수
df5 = pd.DataFrame({
"A": ["a00", "a01", "a02"],
"B": ["a10", "a11", "a12"],
},
index = ["k0", "k1", "k2"])
df5df6 = pd.DataFrame({
"C": ["b00", "b01", "b02"],
"D": ["b10", "b11", "b12"],
},
index = ["k0", "k2", "k3"])
df6
df5.join(df6) #left join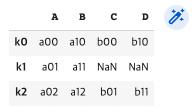
df6.join(df5) #right join
df5.join(df6, how="inner") #inner join
df5.join(df6, how="outer") #outer join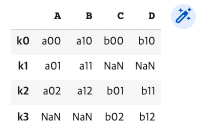
반응형
'Data Science > 데이터분석 (Spark)' 카테고리의 다른 글
| [빅데이터분석] Apache Spark가 각광받고 있는 이유에 대한 백엔드 개발자의 관찰 (1) | 2023.11.27 |
|---|---|
| [빅데이터분석] OpenAPI를 통한 데이터 수집과 MongoDB에 저장하기 (1) | 2023.11.27 |
| [Pandas] 데이터 분석을 위한 판다스 사용법 - 5. 데이터 분석 (0) | 2023.07.06 |
| [Pandas] 데이터 분석을 위한 판다스 사용법 - 4. 데이터 가공 : 자료구조와 원소 변경하기 (0) | 2023.07.05 |
| [Pandas] 데이터 분석을 위한 판다스 사용법 - 3. 데이터 선택 : 조건과 필터 (0) | 2023.07.05 |







