
[빅데이터분석] Apache Spark가 각광받고 있는 이유에 대한 백엔드 개발자의 관찰
<상명대학교 빅데이터분석 임좌상 교수님 수업들 들으면서..>

Apache Spark 는 대규모 데이터 처리 및 분석을 위한 오픈 소스 클러스터 컴퓨팅 시스템이다.
주로 대규모 데이터셋에 대한 분석 작업과, ML 모델의 학습 및 예측, 그래프 처리를 통한 분석 툴, 실시간 데이터 스트림 처리의 용도로 사용되고 있으며, 데이터 분석가들에게 클러스터 컴퓨팅을 통한 병렬 처리라는 장점은 빅데이터 시대에서 Apache Spark가 각광받는 이유라고 생각한다.
1. 빠른 속도 : Spark는 메모리 기반의 데이터 처리를 통해 빠른 속도를 제공한다.
2. 클러스터 컴퓨팅: Spark는 클러스터 상에서 데이터를 처리하도록 설계되었습니다. 여러 노드로 구성된 클러스터에서 데이터 및 작업을 분산하여 처리함으로써 대규모 데이터셋을 효율적으로 처리할 수 있다.
3. 다양한 라이브러리: Spark는 다양한 분석 작업을 지원하는 라이브러리를 포함하고 있다. 머신러닝, 그래프처리, 실시간 데이터 처리 등을 지원하는 다양한 라입러리를 활용할 수 있다.
Spark의 아키텍쳐
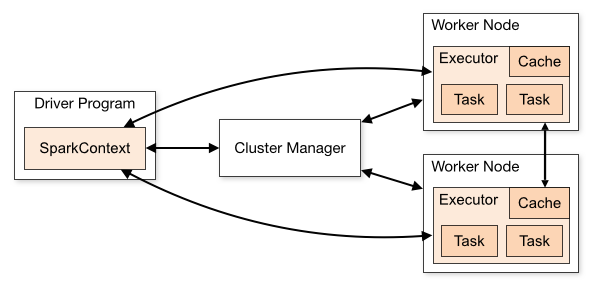
Apache Spark는 클러스터의 형태를 취하고 있다. 여러 컴퓨터들이 연결되어 하나의 시스템처럼 협업하는 체계로서, 몇 개부터 수천 개로 구성할 수 있기 때문에 대규모 데이터 처리와 분석을 위한 분산 컴퓨팅 아키텍쳐로 적합하다고 한다.
Spark는 Master-Slave 아키텍처에 따라, 중앙에 하나의 Driver가 있고, 여러 Worker가 분산되어 있다.
Master Node : Cluster Manager의 역할을 한다. 애플리케이션을 실행하기 위해 작업을 워커 노드에게 자원을 배분한다.
Worker Node : Cluster Manager의 지시에 따라서 작업을 수행하고 결과를 드라이브에 보낸다.
Driver : 클라이언트 측에서 실행하고, Cluster Manager와 통신하여 실행과 작업 분배한다. 애플리케이션의 진입점이자 중앙 제어 포인트이다.
Apache Spark에서 채택하는 클러스터 구조라고 하면 Kubernetes가 일단 가장 먼저 떠오르는 사람들이 많을 것이다.
실제로 Spark는 Cluster Manager의 종류로 Kubernetes를 제공하기도 한다.
Cluster Manager의 종류
- Standalone: 로컬에서 사용하는 경우
- YARN: 초기에는 하둡의 맵리듀스 작업을 위해 개발되었지만, 이후 하둡 2세대에 확장해서 적용,
- Apache Mesos: 자원 공유를 중심으로 설계된 클러스터 관리자.
- Kubernetes: 클라우드 환경 내 컨테이너화된 응용 프로그램의 오픈 소스 플랫폼
Spark는 어떻게 돌아갈까? Hadoop은 또 뭘까?


Hadoop은 데이터가 대량으로 증가하면서, 이를 처리하기 위한 자바 기반의 오픈 소스 분산 플랫폼으로, 클라이언트-서버 방식으로 운영되며 대용량 데이터를 수집하고 병렬 처리하기 위해 사용되고 있다.
HDFS (Hadoop Distributed File System) : Hadoop 자체 파일시스템으로서 제공된다. HDFS에서 데이터를 읽어 MapReduce
작업으로 데이터를 추출, 가공하여 사용된다.
YARN (Yet Another Resource Negotiator) : Hadoop 아키텍처의 Storage Layer 위에 위치한다. 클러스터 노드들의 컴퓨팅 자원을 할당하고, 작업 일정을 계획하고, 작업을 지시하고, 작업이 잘 진행되는지 보고, 장애가 발생할 경우 대처하는 등의 기능을 수행하게 된다.
Spark는 Hadoop을 내장하고 있어 HDFS를 통해서 수집한 데이터를 분석하는 용도로 사용된다.
- 자체 파일 시스템이 없는 대신 RDD를 통해 Hadoop의 파일시스템 HDFS를 사용한다.
- Hadoop과 달리 메모리에서 처리하기 때문에 빠르다.
- 머신러닝, 그래프 처리, 데이터 실시간 처리 라이브러리를 내장하여 데이터 분석에 유연하다.
정리하자면 Spark는 Hadoop을 내장하고 있으며, 데이터 수집과 Map Reduce 배치처리는 Hadoop이 담당하고, Spark는 인메모리 파이프라인을 사용하여 속도가 빠르고 대화식 분석, 스트리밍 처리, 머신러닝 등 데이터 분석에서 유연한 기능들을 제공한다.
Spark의 실행 방식
Spark는 일괄실행과 상호작용 방식으로 크게 나누어 실행한다고 보면 된다.
일괄실행 : 대량의 정적 데이터를 처리하며, 결과를 데이터베이스 등 스토리지에 저장하기 위한 목적으로 사용되는 것이 일반적이다.
Python 프로그램 test.py를 spark-submit 명령어를 통해 일괄적으로 실행하는 것이 해당된다.
spark-submit test.py
상호작용 방식 : 대화식으로 명령어를 입력하고, 즉시 응답을 얻을 수 있도록 진행한다.
Scala, Python Shell, Jupyter Notebook 등 인터렉티브한 대화형 Shell을 이용하며 데이터 집계, 시각화 또는 실험적인 분석을 할 때 유용한 방식이라고 한다.
Spark가 각광받는 이유?
사실 필자는 빅데이터나 인공지능 분야에서 일하는 것보다는 그들 옆에서 백엔드, 더 나아가 DevOps 영역 및 시스템 엔지니어로 일하고 싶은 입장이지만, 그럼에도 불구하고 Apache Spark의 생태계에 대해서는 관심이 갈 수 밖에 없다.
Spark가 각광받게 된 이유는 빅데이터의 특징이 기존의 도구나 방법으로는 감당하기 불충분하기 때문인 것이 가장 큰 것 같다.
기존처럼 하나의 컴퓨팅 자원으로는 처리 자체가 불가능한 규모의 데이터라면, 더이상 예전처럼 하나의 컴퓨터에서 데이터 끌어와서 분석하는 것이 어려워진다는 것이다.
규모가 큰만큼 필요한 컴퓨팅 자원이 많이 투입되어야 하며 이는 Spark와 같은 분산 컴퓨팅이 필요하다는 뜻이다. 처리하는데 필요한 컴퓨팅 자원이 분산되어야 하고, 분산 작업을 실패하지 않고 통합하는 등 제어하는 기능이 필수적이다.
이는 데이터 분석을 찍먹하고 있는 나에게도 백엔드 서버 구축 뿐 아니라 빅데이터를 처리하기 위해서 분산환경이 필수적이라는 점이 인상깊다. (물론 당연하게도 빅데이터가 분산환경의 필요성을 대두시키는 데에 가장 큰 역할을 했겠지만..)
그리고 이는 MSA, 컨테이너 오케스트레이션 등 분산 컴퓨팅 환경에도 관심이 있는 나에게 빅데이터와의 연결점이 될 것 같은 예감이 들기도 한다.
개발자 시장에서도 중요한 이유가 있다. 커뮤니티가 활발하고, 새로운 기능과 업데이트가 빈번하며, 산업적 수요가 높다는 것은 개발자 입장에서 Spark에 관심을 기울어야 하는 이유일 것 같다.
(+) Jupyter notebook에서 Spark 사용하기
pip install pyspark
Spark Session 만들기¶
SparkSession을 Spark 애플리케이션을 실행하기 위한 진입점으로 한다. 이전의 개별적인 SparkContext와 SQLContext를 모두 통합해서 사용할 수 있음.
import os, sys
import pyspark
# os.environ["PYSPARK_PYTHON"]="/usr/bin/python3"
# os.environ["PYSPARK_DRIVER_PYTHON"]="/usr/bin/python3"
myConf=pyspark.SparkConf() #여기에 필요한 설정을 정의한다
spark = pyspark.sql.SparkSession\
.builder\
.master("local")\
.appName("myApp")\
.config(conf=myConf)\
.getOrCreate() #Singleton Create
sys.executable
'/Users/sojaehwi/opt/anaconda3/bin/python'
spark.version
'3.4.1'
!java -version
openjdk version "11.0.11" 2021-04-20 OpenJDK Runtime Environment AdoptOpenJDK-11.0.11+9 (build 11.0.11+9) OpenJDK 64-Bit Server VM AdoptOpenJDK-11.0.11+9 (build 11.0.11+9, mixed mode)
!javac -version
javac 11.0.11
!python --version
Python 3.9.13
spark.conf.get('spark.sql.warehouse.dir') #메타데이터 관리를 위해 자동으로 만들어짐
'file:/Users/sojaehwi/Documents/GitHub/LECTURE_Bigdata/spark-warehouse'
'Data Science > 데이터분석 (Spark)' 카테고리의 다른 글
| [빅데이터분석] Spark RDD 다루기 : 데이터 집계와 Paired-RDD (0) | 2023.11.27 |
|---|---|
| [빅데이터분석] Spark RDD 다루기 : 구조 생성, 데이터 처리 및 Map-Reduce (0) | 2023.11.27 |
| [빅데이터분석] OpenAPI를 통한 데이터 수집과 MongoDB에 저장하기 (1) | 2023.11.27 |
| [Pandas] 데이터 분석을 위한 판다스 사용법 - 6. 데이터 편집 (0) | 2023.07.06 |
| [Pandas] 데이터 분석을 위한 판다스 사용법 - 5. 데이터 분석 (0) | 2023.07.06 |







