
[AWS] 메시지 서비스의 이해 : SQS & SNS & Kinesis

현대의 애플리케이션 아키텍처에서는 서비스 간 결합도를 낮추고 유연한 처리를 가능하게 하기 위해 메시지 큐(Message Queue)를 활용하는 경우가 많다.
특히 마이크로서비스 환경에서는 각 서비스가 독립적으로 동작하면서도 필요한 데이터를 주고받아야 한다.이때 직접 호출 방식 대신 메시지 큐를 사용하면, 서비스 간 결합도를 낮추고 장애 복원력과 확장성을 높일 수 있다.
AWS는 이런 메시지 기반 아키텍처를 손쉽게 구축할 수 있도록 다양한 서비스를 제공한다. 이번 포스팅에서는 AWS가 제공하는 대표적인 메시지 서비스인 SQS와 SNS의 특징과 유스케이스를 살펴보려고 한다.
AWS의 메시지 서비스
AWS에서는 다양한 메시지 서비스들을 제공하여 아키텍처의 디커플링(Decoupling), 즉 구성요소 간의 의존성을 낮추고 유연성을 확보할 수 있도록 지원한다. 주요 서비스는 다음과 같다.
- Amazon SQS (Simple Queue Service) : 기본적인 메시지 서비스. 비동기 메시지 큐 지원
- Amazon SNS (Simple Notification Service) : Pub/Sub 기반 브로드캐스트 메시지 서비스
- Amazon Kinesis : 스트리밍 데이터 수집 및 처리를 위한 메시지 스트리밍 서비스
- Amazon MQ : 전통적인 큐 기반 메시지 브로커 (Apache ActiveMQ, RabbitMQ 기반)
- Amazon MSK : Apache Kafka 기반의 메시지 브로커
- 기타 이벤트 기반 기능: S3 Event, EventBridge, DynamoDB Streams
메시지 브로커와 메시지 서비스
AWS에서는 SQS와 SNS, Kinesis를 메시지 브로커가 아닌 메시지 서비스로 분류한다.
RabbitMQ, ActiveMQ, Kafka처럼, 독립된 서버나 클러스터가 메시지를 중개할 때 브로커라는 용어를 사용한다. 즉 AWS에서는 브로커 인프라를 운영하는 서비스에만 이 표현을 사용한다. 반면 SQS와 SNS는 사용자가 브로커를 직접 관리하지 않기 때문에 "메시지 서비스"로 구분한다.
즉 "SQS와 Amazone MQ", "Kinesis와 MSK"는 각각 유사한 목적으로 사용되지만 SQS와 Kinesis는 서버리스 기반의 완전 관리형 서비스이고 Amazon MQ와 MSK는 브로커 인프라를 기반으로 세밀한 제어가 가능한 서비스라는 점에서 구분된다. 즉 운영대행의 여부에 따라서 구분된다고 생각하면 된다.
SQS (Simple Queue Service)
- 사용 목적 : 시스템 아키텍처에서는 주로 서비스에서 다른 서비스로 데이터를 전달할 때 활용
- 대표적으로 마이크로서비스 아키텍처에서의 통신, 예를 들어 주문 시스템에서의 주문 완료 시 결제 시스템으로의 메시지 전달
- Serverless로 분류, 큐의 대기 메시지 수를 기준으로 Auto-scaling 정책에서 활용하는 등 다른 서비스와 연계 가능
- 처리 방식
- 비동기 통신 모델 : 생산자와 소비자가 독립적으로 동작
- 메시지 소비 방식 : Polling 방식의 메시지 소비 (주기적으로 API 요청), 메시지 처리 이후 삭제하는 과정 필요
- 순서 보장 및 중복 처리
- 기본적으로 처리 순서가 보장이 되지 않으며, 메시지가 한 번 이상 전달(At Least Once)될 수 있다. 따라서 로직이 여러 번 수행되더라도 동일한 결과를 보장할 수 있도록 멱등성(Idempotency) 확보 필요
- 그렇지만 FIFO Queue를 사용하면 순서 보장 및 정확히 1회 전달(Exactly Once Delivery)
- 종류 : SQS Standard와 SQS FIFO로 구분
- 접근 : Public 접근 가능 → 인터넷에서 접근 가능하기 때문에 SQS 접근 주체에 대한 액세스 정책 관리 필요
- 장점: 성공 여부 파악 및 재처리 가능(자동 재시도, Dead Letter Queue 연동 등)
- 단점: 처리 성공 여부를 매번 직접 명시 필요, 누락 시 중복 처리 위험
구성 요소

- Message : 전달되는 데이터의 기본 단위
- Producer : 메시지를 생산하여 SQS에 푸시
- Consumer : 메시지의 소비자. Polling 방식의 메시지 소비
- Queue : 메시지를 저장하고 관리
- Dead Letter Queue(DLQ) : 처리에 실패한 메시지를 모아두는 서브 큐, 설정한 재시도 횟수보다 많이 실패했을 경우 DLQ로 전달 → 재처리 가능
Message
SQS의 Message는 아래와 같은 포멧으로 구성된다.

- Message Body : 메시지의 내용, String, 최대 256Kib
- Message Attribute : Key-Value 형식의 메타데이터. 주로 분류, 필터링, 처리 방식 지정 등에 활용, 최대 10개까지 지정 가능
- Message System Attribute : AWS 서비스에서 활용하기 위한 메타데이터
- ReceiptHandle : 메시지를 삭제하기 위한 Key
- Message Group ID, Deduplication ID : FIFO 타입의 경우 포함
- 메시지 상태 : Stored(저장 및 대기) → In Flight(소비 중) → Deleted(처리 완료 삭제)
Visibility Timeout
메시지가 Consumer에서 소비될 때 일정 시간 동안 잠금 상태로 만들어 중복 처리를 방지하기 위한 메커니즘
- 해당 시간 안에 메시지 처리 완료 이후 삭제하는 과정이 필요 → 그렇지 않으면 다른 컨슈머가 중복 처리할 수 있음
- 메시지를 처리하기 충분한 시간, 오류 및 에러 상황에 대응할 수 있는 시간 설정 필요
- 기본적으로는 Queue 단위 설정, 필요에 따라 Message 단위로 설정 가능
다음 그림은 Message의 중복 처리 방지 메커니즘을 나타낸다.

- 메시지 전송 : Component 1이 Message A를 큐에 보낸다.
- 메시지 수신 및 잠금 : Component 2가 Message A를 가져가면서 Visibility Timeout이 시작된다. 이 동안 다른 Consumer는 같은 메시지를 볼 수 없다.
- 메시지 처리 및 삭제 : Component 2가 메시지를 처리하고, Visibility Timeout이 만료되기 전에 삭제한다. 삭제하지 않으면 Timeout 후 다시 큐에 나타나 다른 Consumer가 가져갈 수 있다.
Polling 방식

Message는 AWS에서 제공하는 SQS Service의 분산 서버에 저장된다. Consumer는 Polling 방식으로 Message를 소비한다고 했다. 이 때 사용되는 Polling 방식은 크게 두 가지로 나눌 수 있다.
- Short Polling(기본) : 큐를 부분 단위(SQS Queue의 일부 Server)로 조회하기 때문에 응답이 빠르며, 메시지가 없어도 즉시 응답하기 때문에 비어있는 응답(False Empty Response)의 빈도가 높음
- Long Polling (권장) : 큐 전체를 조회, 메시지가 없다면 Timeout시까지 대기한 이후 응답 → 비어있는 응답 방지, 트래픽과 비용 절감
SQS Queue Type
앞에서 SQS의 Queue의 타입은 크게 두 가지로 설정할 수 있다고 했다.
- SQS Standard : 처리 순서를 보장하지 않음, 메시지를 한 번 이상 전달할 수 있음(At Least Once)
- 멱등성(Idempotency) 확보 필요 : 로직이 여러 번 수행되더라도 동일한 결과 보장
- SQS FIFO : 순서 보장, 메시지를 단 한번만 전달하도록 보장(Exactly Once Delivery), Standard에 비해 성능 제약
- 목표 : 메시지의 순차적 처리(FIFO) 및 처리 여부 보장 가능, 하나의 메시지를 하나의 서비스에서 단 한 번만 처리하는 것
- Deduplication ID : SQS에서 각 메시지의 중복 여부를 판단하기 위한 고유 토큰 → 이미 처리된 경우 같은 ID를 가진 메시지를 5분간 무시 (성공은 정상적으로 반환, 메시지만 무시)
- 자동 방식 (Content Based) : SQS에서 자동으로 Body의 해쉬를 Deduplication ID으로 활용하는 방식
- 수동 방식 : Producer가 직접 Body에 Deduplication ID를 생성해서 같이 전달하는 방식
- Message Group : 같은 그룹의 메시지에 대해서 순서 보장 → 동일한 Message Group ID를 가진 메시지는 동시에 하나만 처리 가능

위 그림은 SQS FIFO Queue에서 Message Group을 기준으로 순서가 어떻게 보장되는지를 보여준다.
같은 Message Group ID를 가진 메시지들은 반드시 순서를 지켜서 처리되며, 동시에 하나의 Consumer만이 가져가게 된다.
- Consumer 1은 Message Group A와 Message Group B를 소비하고, Consumer 2는 Message Group B를 소비한다고 가정하자.
- Group A의 메시지(A1, A2, A3...)는 순서를 지켜 Consumer 1이 처리하고, Group B의 메시지(B1, B2, B3...)는 별도로 Consumer 2가 처리하였다.
- 이후 Consumer 1은 Consumer 2가 처리한 Group B의 메시지를 소비하지 않고 B11부터 소비하기 시작한다.
이처럼 FIFO Queue는 Group 단위로 순서를 보장하면서도, Group 간의 중복 처리를 방지하고 병렬 처리가 가능하다는 특징을 가진다.
Visibility Timeout과 Deduplicated ID의 차이점
- Deduplication ID는 같은 메시지가 FIFO 큐에 중복 전송되는 것을 방지하는 것
- Visibility Timeout은 메시지 수신 후 다른 Consumer가 재처리하지 않도록 일정 기간동안 숨김 처리하는 것.
- 둘 다 중복을 막지만, Deduplication은 발송 중복 방지, Visibility Timeout은 수신 중복 방지
<함께 보기> AWS + Spring : SQS를 활용한 애플리케이션 간 비동기 통신 적용 (Standard & FIFO 비교)
https://sjh9708.tistory.com/271
[AWS + Spring] SQS 활용 : 메시지 큐 기반 비동기 통신 구현
현대의 시스템 아키텍쳐에서 시스템 간 데이터를 주고받을 때, 처리를 즉시 완료하지 않아도 되는 작업이라면 비동기 메시징 방식이 효과적으로 사용된다.특히 마이크로소프트 아키텍쳐를 위
sjh9708.tistory.com
SNS (Simple Notification Service)

- 사용 목적 : 시스템 아키텍처에서는 하나의 이벤트를 여러 서비스나 주체에 동시에 전달(Fan Out)할 때 활용
- A2A(Application to Application) 및 A2P(Application to Person) 통신을 위한 메시징 서비스
- Serverless로 분류, 다양한 전송 채널(Email, SMS, HTTP, Lambda, SQS 등)과 연계 가능
- 예시로 주문 완료 시 결제 시스템, 재고 관리 시스템 등에 동시에 메시지를 전달하며 운영자 이메일로 알림 전송
- CloudWatch의 Alarm 전파에도 SNS를 기반으로 사용된다.
- 처리 방식
- Pub/Sub 통신 모델 : Publisher와 Subscriber가 독립적으로 동작
- 메시지 전송 방식 : 하나의 Topic에 메시지를 Publish하면, 구독(Subscribe)한 모든 대상에게 메시지가 Push되어 전달
- 순서 보장 및 중복 처리
- 기본적으로 순서가 보장되지 않으며, 수신 주체에 따라 중복 처리가 발생할 수 있음
- FIFO Topic을 사용할 경우, 순서 보장 및 정확히 1회 전달(Exactly Once Delivery) 가능
- 단, FIFO Topic은 SQS Queue와만 연동 가능 (Email, HTTP 등은 불가)
- 종류 : Standard Topic과 FIFO Topic으로 구분
- 접근 : Public 접근 가능 → 인터넷에서 접근 가능하기 때문에 SNS Topic에 대한 액세스 정책 관리 필요
- 장점 : 다양한 전송 방식 지원 (Email, HTTP, Lambda, SQS 등) 및 Fan-Out 구조 구현 가능
- 단점 : 동적 수신자 지정이 어려움 → 수신 대상을 유연하게 변경하려면 Lambda 등 추가 구성 필요
구성 요소
- Topic : SNS의 주요 관심사 단위이자 채널, 해당 토픽에 Message를 Publish하면 Subscribe한 모든 대상에게 메시지를 발송
- Publisher : 메시지를 생산하고 SNS Topic에 전달하는 주체
- Subscriber : Topic으로부터 메시지를 받아서 처리하는 주체
- Message : SNS에서 전달하는 데이터
- 구독 프로토콜 : 이메일, HTTP(S), SQS, SMS, Lambda, Kinesis Data Firehose, 최초 구독 시 확인 필요 (확인 이메일, Lambda의 경우 확인 이벤트)
Message

- Message Body : 메시지의 실제 내용(String). 주로 알림의 본문에 해당하며, 최대 256KiB까지 저장 가능
- Message Attribute : Key-Value 형식의 메타데이터. 수신 필터링, 메시지 분류, 처리 방식 지정 등에 활용할 수 있으며 최대 10개까지 추가 가능
- System Attribute : 전송 시 자동 추가되는 메타데이터로 Topic ARN, Timestamp, Signature, 구독 해제 URL 등 포함
- TTL : 모바일 전송용으로, 지정된 기간 내에 전송되지 않으면 메시지가 삭제되는 기능
- Raw Message Delivery : 구독자가 SNS 시스템 포맷(JSON) 대신 순수 Message Body만 수신하도록 설정 가능
- Message Structure : 플랫폼별(Email, SMS, Mobile Push)로 다른 메시지 포맷을 설정할 수 있는 기능 (선택적 사용)
SQS와 SNS의 메시지 처리 방식의 차이
- SQS는 메시지를 큐에 저장하고 Consumer가 가져가서 수동으로 삭제해야 하는 모델이지만 SNS는 메시지를 발행(Publish)하면 구독자들에게 바로 전달하고 저장하지 않는다.
- SQS는 ReceiptHandle을 이용해 삭제 과정을 관리하지만, SNS는 별도 삭제 절차가 없다. 따라서 Visibility Timeout도 존재하지 않는다.
- SQS는 Polling 방식, 즉 클라이언트가 메시지 큐를 주기적으로 조회하여 소비하는 구조이다.
- SNS는 Push 방식, 즉 발행된 메시지를 구독자에게 즉시 전송(Push) 하여 구독자가 별도의 조회 없이 메시지를 수신하는 구조이다.
SNS의 다양한 지원 기능
- Raw Message Delivery : SNS 메시지 포멧을 따르지 않고 전달받은 메시지를 그대로 전달 가능
- S3 로깅, 이메일로 내용 전송 등 메시지를 JSON 형식으로 파싱하지 않고 그대로 전송해야 하는 경우 사용
- 메시지 필터링 : Subscription Filter Policy 설정을 통해 특정 메시지만 수신하도록 설정 가능
- Body 혹은 Attribute 단위로 메시지 매칭, 매칭 시에만 메시지 발송
- 예를 들어 특정 기기에서는 메시지의 Attribute에 “국가”가 “대한민국”인 메시지만 수신
- Amazone SNS Data Protection : SNS의 메시지 중 민감한 정보를 감지하는 서비스
SNS FIFO
SQS와 마찬가지로 SNS Topic도 FIFO 타입으로 설정할 수 있다. SNS FIFO는 메시지 순서 보장, 중복 제거, 메시지 보관 및 리플레이 기능을 제공한다.

- Message Group : 같은 그룹의 메시지에 대해서 순서를 보장하며, 동일한 Message Group ID를 가진 메시지는 동시에 하나만 처리 가능
- Message Sequence Number : 항상 증가하는 일련번호를 메시지에 부여하여, Subscriber가 수신 순서를 정확히 유지할 수 있도록 지원
- Deduplication ID : 중복 메시지 여부를 판단하는 고유 토큰
- 자동 방식(Content Based) : SNS에서 Body 내용을 해시하여 Deduplication ID로 사용
- 수동 방식(Explicit) : Producer가 직접 Deduplication ID를 생성하여 함께 전송
- 연동 제약 : FIFO Topic은 SQS Queue와만 연동 가능하며, Email, SMS, HTTP 엔드포인트 등 일반적인 Subscriber와는 연동할 수 없음
- 주로 여러 SQS Queue에 대해 순서를 유지하며 메시지를 Fan-Out하는 용도로 활용
- Message Archive & Replay : FIFO Topic에 발행된 메시지를 저장하고, 필요할 때 다시 전송(Replay)할 수 있는 기능
- 메시지 전달 오류 복구, 장애 복구, 신규 시스템과의 데이터 동기화 등에 활용
실전 아키텍쳐 분석
이 아키텍처는 AWS Lambda, Amazon SNS FIFO, Amazon SQS(FIFO/Standard)를 조합하여 메시지를 다양한 시스템으로 분배하는 구조를 갖고 있다.
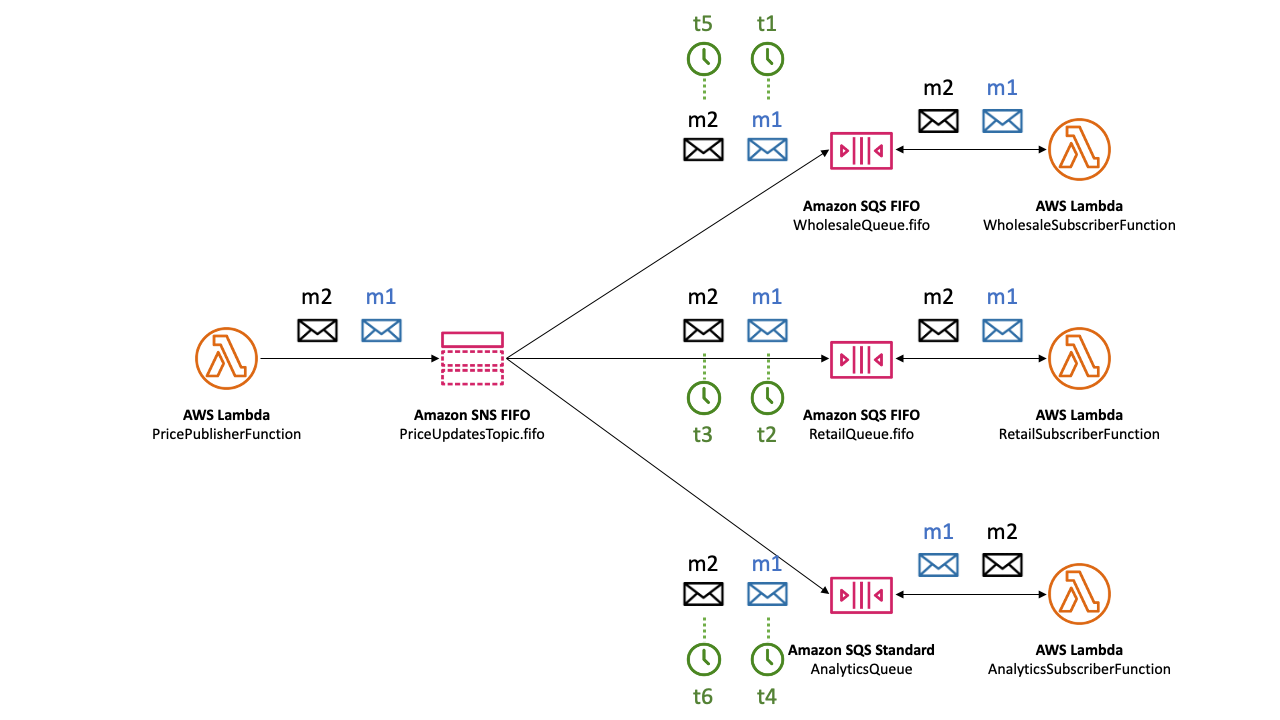
- PricePublisherFunction Lambda 함수가 가격 변경 이벤트(m1, m2)를 Amazon SNS FIFO Topic(PriceUpdatesTopic.fifo)에 발행한다.
- SNS FIFO Topic은 메시지 순서와 중복 제거를 보장하며, 발행된 메시지를 여러 SQS Queue로 브로드캐스트한다.
- SNS Topic은 다음 3개의 SQS Queue에 메시지를 전달한다.
- WholesaleQueue.fifo (FIFO Queue) : 도매 시스템용
- RetailQueue.fifo (FIFO Queue) : 소매 시스템용
- AnalyticsQueue (Standard Queue) : 분석 시스템용
- WholesaleQueue.fifo와 RetailQueue.fifo는 각각 FIFO 특성에 따라 m1 → m2 순서를 유지하며 메시지를 수신한다.
- 이 메시지들은 각각 WholesaleSubscriberFunction, RetailSubscriberFunction Lambda 함수에서 순차적으로 소비된다.
- AnalyticsQueue는 Standard Queue로 구성되어 있어 순서 보장 없이 m1과 m2 메시지를 병렬적으로 받아 AnalyticsSubscriberFunction Lambda 함수에서 처리된다.
- 분석 작업은 순서에 민감하지 않기 때문에 처리 속도를 우선시한 구조이다.
Amazon Kinesis

대규모 실시간 스트리밍 데이터를 수집, 처리, 분석할 수 있도록 지원하는 AWS의 관리형 서비스이다.
Kafka와 유사한 사용 목적을 가지지만, 마이크로서비스 간 통신이나 데이터 동기화 등에는 많이 사용되지 않고 로그 수집, 센서 데이터 처리, 대량 데이터 분석 등에 더 최적화되어 있다.
Kinesis는 다음과 같은 4가지 주요 서비스로 구성되어 있다.
- Kinesis Data Streams : 스트리밍 데이터를 실시간으로 수집하는 핵심 서비스. 스트리밍 데이터를 모아서 Consumer가 직접 읽고 처리하는 구조
- Kinesis Data Firehose : 수집 → 변환 → 저장까지 자동화된 데이터 파이프라인 제공. 수집된 데이터를 가공하여 S3, OpenSearch, Redshift 등 다양한 대상에 실시간으로 전달
- Kinesis Data Analytics : 수집된 스트리밍 데이터를 SQL 기반으로 실시간 분석
- Kinesis Video Streams : 동영상 스트림 데이터를 캡처, 저장, 분석 (재생, 머신러닝 연계 등)
다양한 클라이언트에서 업로드하는 로그 데이터를 Kinesis Data Streams로 수집하고, 이를 실시간으로 분석하기 위해 Kinesis Data Analytics를 연결하거나 또는 별도로 Kinesis Data Firehose를 통해 S3, OpenSearch 등으로 저장하고 후속 분석을 수행할 수 있다.
Kinesis Data Streams
Kinesis Data Streams는 실시간 스트리밍 데이터의 수집, 저장, 분배를 담당하는 Kinesis 아키텍처의 핵심 출발점이다. Kinesis Data Analytics, Firehose 등의 상위 서비스들은 Data streams로 수집된 데이터를 기반으로 기능을 제공한다.
- 스트리밍 데이터 수집 및 전달 : 요청(Request) 기반이 아닌, 지속적으로 생성되는 데이터(로그, 이용 데이터, 센서 데이터 등) 를 처리
- 즉 데이터가 발생하는 대로 불특정 다수의 클라이언트(Producer)가 Kinesis 스트림에 Push하고, Consumer 또한 해당 데이터를 지속적으로 Polling하여 처리한다.
- 구성 요소
- Data Stream : 샤드(Shard)로 구성된 데이터 처리를 위한 스트림
- Shards : Data Stream의 처리 단위로서 내부 파이프라인 역할. 일정 크기의 데이터를 처리하는 단위로서 Data Stream의 처리 가용량은 샤드의 수에 따라 결정된다.
- 순서 보장 : Partition Key를 기반으로 Shard 단위 내부에서의 순서를 보장한다.
- Read : [5 Transaction / sec], [2MB / sec] & Write : [1000 record / sec], [1MB / sec])
- Reshard : Shard를 분할(Split) 혹은 병합(Merge). 샤드의 숫자 조절 가능
- Update Shard : Background에서 샤드 숫자를 조절(병합 & 분할)
- 상태
- Open : 활성화된 Shard. 데이터 발신, 수신 가능
- Close : 남아있는 데이터 발신 가능, 신규 데이터 수신 불가능 → 즉 Shard 수가 조절되는 과정에서 남아있는 데이터만 처리할 수 있는 상태
- Expired : 더이상 사용하지 않는 Shard. Closed된 Shard가 모든 데이터를 처리했다면 상태가 변경됨.
- Data Record : 스트림 내에서 전달되는 데이터 단위, Sequence Number 부여 (Shard+Partition Key 기준)
- Producer : 데이터를 스트림에 전달하는 주체
- Consumer : 데이터를 스트림에서 읽어 처리하는 주체
- Capacity Mode
- On-Demand Mode : 자동으로 샤드를 확장, 예측 불가능한 데이터량에 대응
- Provisioned Mode : 샤드 수를 직접 설정하고 운영
- 데이터 전송 방법 (Producer 측)
- PutRecord(s) API : 직접 API 호출로 데이터 전송
- Kinesis Producer Library(KPL) : 데이터 전송 최적화를 지원하는 라이브러리
- Kinesis Agent : 서버나 장비에 설치하여 자동으로 데이터 전송(Java 기반)
- 데이터 소비 방법 (Consumer 측)
- Kinesis Client Library(KCL) 를 사용하여 데이터를 읽고 처리 가능
- 지원 언어 : Java, Python, Node.js, .NET 등
- 중복 처리 : Kinesis는 시스템 차원의 중복 방지 기능을 제공하지 않는다. Producer의 전송 실수나 재시도로 인한 중복을 감지하지 않고 들어오는 데이터를 모두 처리하기 때문에 필요하다면 Consumer 또는 애플리케이션 레벨에서 Idempotency(멱등성) 처리를 직접 구현해야 한다.
정리
| Amazone SQS | Amaznoe SNS | Amaznoe Kinesis | |
| 통신 모델 | Point-to-Point (1:1) | Publish-Subscribe (1:N) | Stream-based (다수 Consumer 처리) |
| 메시지 처리 방식 | 저장 후 Consumer가 Polling하여 가져감 | 저장 없이 발행 후 Subscriber에게 Push 전송 | 스트림에 Push 후 Consumer가 Polling하여 처리 |
| 순서 보장 | Standard: 없음 / FIFO: 순서 보장 | Standard: 없음 / FIFO: 순서 보장 (단, FIFO는 SQS만 구독 가능) | Shard 단위 순서 보장 (Partition Key 기반) |
| 중복 처리 | Standard: 중복 발생 가능 FIFO: Deduplication ID로 중복 제거 |
Standard: 중복 발생 가능 FIFO: Deduplication ID로 중복 제거 |
중복 여부를 직접 판단 및 처리 필요 |
| 메시지 삭제 필요 여부 | 필요 (ReceiptHandle 이용) | 불필요 (즉시 전송) | 불필요 (Retention 기간 내 자동 저장 후 만료) |
| 사용 목적 | 비동기 작업 대기열, 서비스 간 비동기 통신 | 이벤트 발생 시 다수 시스템에 동시에 알림 전파 | 대규모 실시간 로그 수집, 분석 파이프라인 구축 |
| 유스케이스 | 주문 처리 후 배송 시스템으로 비동기 전달 | 주문 완료 시 이메일, SMS, 재고관리 시스템에 동시에 알림 | 서버/디바이스 로그를 실시간으로 수집 및 분석 시스템으로 스트리밍 |
References
https://docs.aws.amazon.com/
docs.aws.amazon.com
쉽게 설명하는 AWS 기초 강의 강의 | AWS 강의실 - 인프런
AWS 강의실 | , 안녕하세요. AWS 강의실입니다.AWS 공식 커뮤니티 빌더이자 2만명의 구독자를 보유한 AWS Only 강의 유튜브의 경험으로 AWS를 쉽게 알려드립니다.이 강의는AWS의 서비스 및 활용 지식을
www.inflearn.com
'Backend > AWS' 카테고리의 다른 글
| [AWS + Spring] SNS 활용 : 이벤트 메시지 브로드캐스트 구현 (0) | 2025.05.01 |
|---|---|
| [AWS + Spring] SQS 활용 : 메시지 큐 기반 비동기 통신 구현 (Standard & FIFO) (1) | 2025.04.30 |
| [AWS] CloudTrail : AWS 리소스 활동 기록 및 감사 로그 추적 (0) | 2025.04.06 |
| [AWS] CloudWatch : 기타 기능 (Dashboard, Synthetics, Resource Health) (1) | 2025.04.04 |
| [AWS] CloudWatch : 주요 개념과 구성요소 (로그, 지표, 경보) (0) | 2025.03.23 |







