
[AWS] CloudWatch : 주요 개념과 구성요소 (로그, 지표, 경보)

이번 포스팅에서는 AWS 인프라를 포함한 시스템을 모니터링 할 수 있는 서비스인 AWS CloudWatch의 주요 구성 요소에 대해서 살펴보려고 한다.
AWS Cloudwatch
CloudWatch는 AWS에서 제공하는 모니터링 서비스로 다양한 AWS 서비스와 애플리케이션의 로그, 지표, 이벤트 등의 운영 데이터를 수집하고 시각화할 수 있다.
- 운영 데이터 수집: 로그(Log), 지표(Metric), 이벤트(Event) 등 다양한 형태의 데이터를 수집한다.
- 모니터링 및 시각화: 실시간 대시보드로 데이터를 시각화하고 시스템 상태를 모니터링할 수 있다.
- 경보(Alarm) 기능: 특정 조건에 따라 경보를 생성하고, SNS, Lambda, EC2 Auto Scaling 등과 연계해 자동화된 대응을 수행할 수 있다.
- 광범위한 연동성: 대부분의 AWS 서비스(ECS, Lambda, RDS, EC2 등) 뿐만 아니라 온프레미스 인프라와 연동 가능하다.
- Public Service: 인터넷 또는 Interface Endpoint를 통해 접근할 수 있는 Public 서비스이다.
- 이벤트 중심 대응: CloudWatch Events와 CloudWatch Logs Insights를 활용해 이벤트 기반 자동화와 고급 로그 분석이 가능하다.
주요 구성 요소
- 지표(Metric): 리소스의 성능이나 상태를 수치화한 데이터, 시간 단위로 수집되어 시계열 그래프로 분석 가능하다.
- 경보(Alarm): 지표에 설정한 임계값을 기준으로 조건이 충족되면 알림을 보내거나 자동화된 작업을 수행하도록 설정할 수 있는 기능
- 로그(Log): 애플리케이션이나 시스템에서 생성된 로그 데이터를 수집·저장·분석하여 문제 해결이나 지표화 용도로 활용 가능
로그(Log)
CloudWatch의 핵심 기능. AWS 서비스 뿐만 아니라 온프레미스 서비스에서 수집한 로그 수집 및 확인 가능.
- 핵심 기능 : 로그 수집, 실시간 모니터링, 로그 수명 주기 관리, 쿼리 기능, 수집된 로그 전달(Kinesis, S3 등 다른 서비스 및 계정으로 전달)
- 구성 요소
- 로그 그룹 : 로그의 관리 단위, 애플리케이션/서비스/리소스 단위로 분류
- 로그 스트림 : 같은 소스에서 순차적으로 받은 로그들의 집합 (ex : 특정 인스턴스 ID에서 수집된 로그의 집합)
- 로그 이벤트 : 타임스탬프와 데이터로 구성된 이벤트 로그 그 자체
- 보존 기간 : 로그의 보관 기간 설정 가능. 무한정 보관도 가능.
- 로그 클래스 : 로그의 사용 용도나 빈도에 따른 분류체계. 로그 그룹 생성 이후 변경 불가능.
- Standard : 실시간 모니터링이 필요한 자주 사용되는 로그, 디폴트
- Infrequent Access : 자주 사용되지 않는 로그, 비용이 저렴하지만 일부 기능만 활용 가능
- 추가 기능
- Log Insights : 대화식 검색으로 CloudWatch 로그를 분석할 수 있는 서비스. JSON으로 구성된 로그 쿼리 가능.
- Metric Filter : 로그에 필터 적용 → 필터링 된 로그를 지표(Metric)으로 변환하는 기능. 필터가 적용된 시점부터 지표화.
- Live Tailing(실시간 로그 확인), 이상 탐지(ML 기반 패턴 탐지), Log Subscription(실시간으로 다른 서비스(스토리지)로 로그 전달)
로그 그룹과 로그 스트림

- 로그 그룹: 유사한 로그 스트림들을 묶는 상위 단위로, 일반적으로 애플리케이션 또는 서비스 단위로 구분하여 사용한다.
- 로그 스트림: 하나의 로그 그룹 안에 포함되는 로그 데이터의 흐름, 일반적으로 각 인스턴스나 컨테이너별로 구분하여 로그들이 저장된다.
로그 이벤트
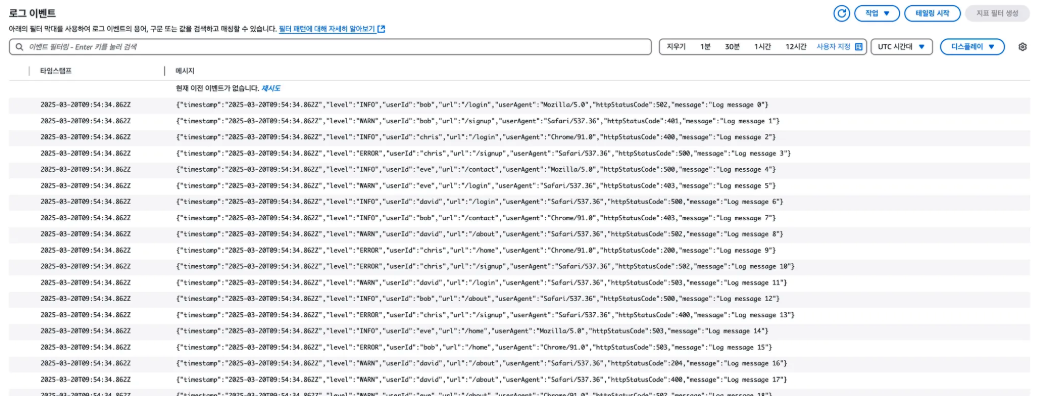
- 로그 이벤트: 로그 스트림에 포함되는 실제 로그 데이터. 시간 순으로 로그 이벤트들이 저장된다.
로그 인사이트 (Logs Insights)
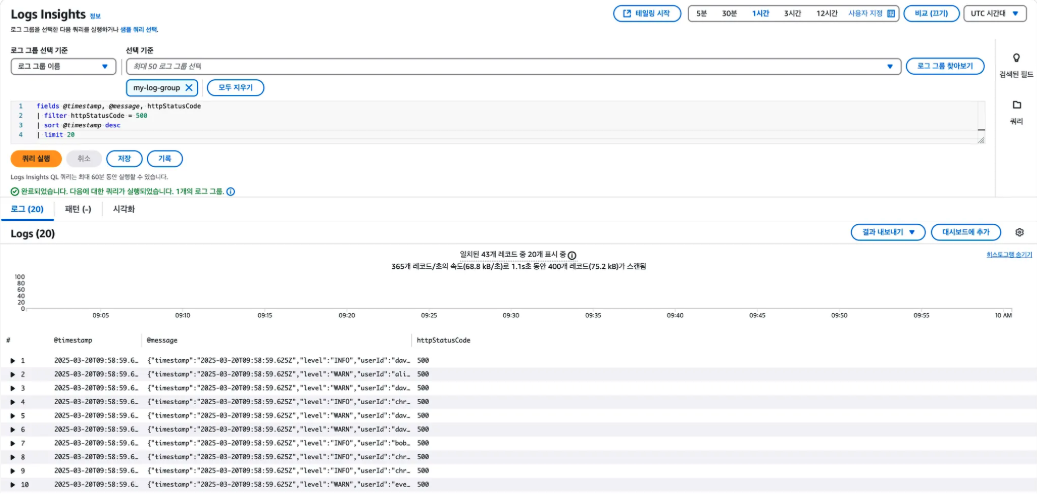
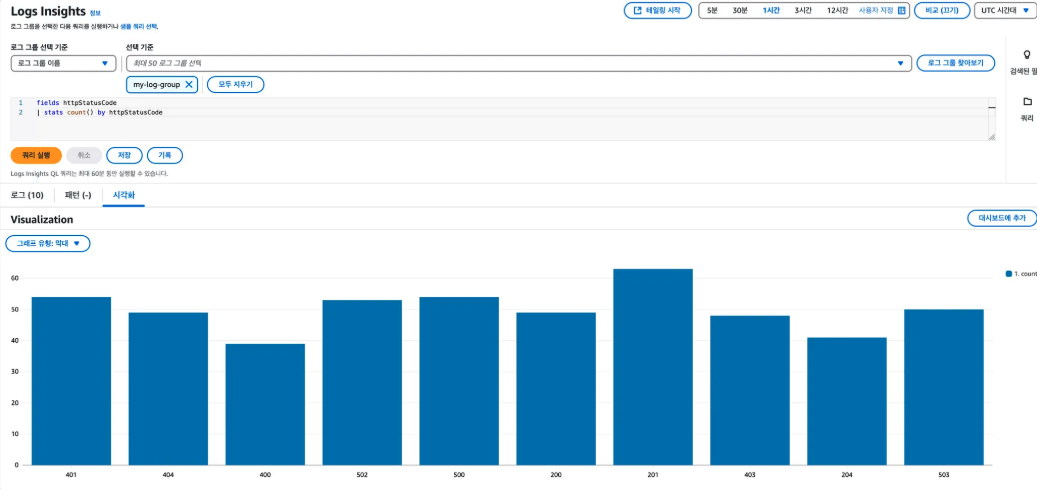
- CloudWatch에 수집된 로그 데이터를 빠르게 검색하고 분석할 수 있는 쿼리 도구
- 예를 들어 에러 로그 수를 시간대별로 집계하거나, 특정 키워드를 포함한 로그만 필터링해 추적하는 것과 같이 다용도로 사용됨
- SQL 유사한 전용 쿼리 언어를 사용해 복잡한 조건의 로그 검색, 필터링, 집계, 시각화가 가능
- 분석 결과는 대시보드에 시각화하거나, 알람 설정과도 연계할 수 있어 운영 문제의 원인 파악 및 대응에 유용
지표(Metric)
- 지표(Metric) : 시간 순으로 정렬된 데이터 포인트(Data Point)들의 집합, 각 데이터 포인트는 시간과 값으로 구성된다.
- 커스텀 지표(Custom Metric) : 기본 수집 항목 외에 직접 원하는 데이터포인트를 생성하여 CloudWatch로 전달 가능.
- 예를 들어 EC2의 CPU, 네트워크, Disk I/O 등은 기본 수집 가능하지만 EC2의 메모리 사용량을 커스텀 지표를 통해 수집 가능.
- 네임스페이스(Namespace) : 지표의 성격에 따라서 논리적으로 묶은 단위, CloudWatch 지표의 컨테이너
- AWS에서 수집하는 기본적인 지표는 "AWS/{서비스명} "형식의 네임스페이스로 구분
- 지표 이름(Metric Name) : 무엇에 관한 지표인지를 명시.
- 데이터 포인트(Data Points) : 지표를 구성하는 시계열 데이터(시간-값)의 단위, Timestamp로 UTC 기준 권장
- Resolution: 데이터 포인트의 수집 주기
- AWS CloudWatch에서는 기본적으로 1분(standard resolution) 또는 1초(high-resolution) 단위로 메트릭 데이터를 수집할 수 있음.
- Resolution에 따라 보관 기간이 존재하며, 작은 Resolution 단위의 데이터는 시간이 지나면 더 큰 단위로 합쳐짐.
- Period: 데이터를 조회 시 집계 단위
- 특정 시간 단위(예: 1분, 5분, 1시간 등)로 데이터를 그룹화하여 보여주는 개념.
- 즉 여러 데이터 포인트를 집계(aggregation) 해서 하나의 값으로 나타내는 시간 간격.
- 데이터가 2주 이상 데이터가 업데이트가 되지 않는 경우 지표가 콘솔에서 보이지 않음 → CLI에서 조회 가능
- Resolution: 데이터 포인트의 수집 주기
- 차원 (Dimension) : Metric을 구분할 때 사용되는 일종의 태그, Key-Value로 구성, 최대 30개까지 할당 가능.
- 예를 들어 여러 개의 EC2 인스턴스의 지표를 구분하기 위해서 인스턴스 ID 차원을 통해서 확인 가능.
- 단위 (Unit) : 지표의 단위. 퍼센트(메모리, CPU 사용률 등), 카운트(호출 횟수 등), 초(실행 시간 등)...
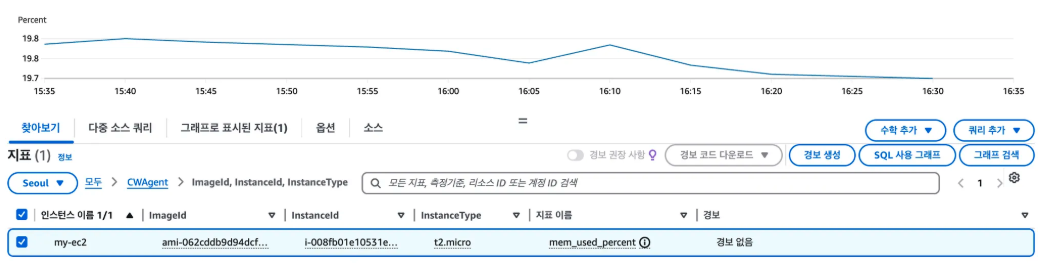
위의 사진을 보며 지표의 개념에 대해서 다시 살펴보자.
- 지표 : EC2 인스턴스의 메모리 사용률(mem_used_percent)을 나타내는 지표
- 메모리 사용률은 CloudWatch Agent를 설치하고 커스텀 지표로 설정해야 수집할 수 있는 항목이다.
- 지표 단위는 Percent이다.
- 지표 이름 : mem_used_percent
- 네임스페이스 : CWAgent
- 이것은 AWS Cloudwatch Agent를 활용하여 커스텀 지표를 수집할 때의 디폴트 네임스페이스이다.
- 차원 : 특정 인스턴스를 구분하기 위한 차원의 요소.
- ImageId(ami-062cddbs...), InstanceId(i-00f8b0e1...), InstanceType(t2.micro)으로 구분
- 수집 주기(Resolution)은 기본적으로 1분 단위를 사용했으며, 집계 단위(Period)를 5분 단위로 설정했을 때 보여지는 데이터 포인트의 모습이다.
경보 (Alarm)
- 경보 기능 : 수집된 지표 값의 변동(임계값)에 따라 발생하는 알림(이벤트) 생성
- 다양한 방법으로 대응 자동화 : 경보 발생 시 SNS(Notification Service)로 Lambda 실행, Slack, 이메일 등을 통해 전달 등
- 상태 : OK(정상 상태), Alarm(경보 상태), INSUFFICIENT_DATA(수집 데이터 부족)
- 경보 주기 : 지표의 Resolution에 따라서 경보의 평가 주기가 달라진다.
- 결합 경보(Composite Alarm) : 여러 경보를 논리적으로 결합한 정보, Boolean 관계(AND, OR, NOT)으로 조건 설정 가능.
- 예를 들어 CPU 사용량 + 네트워크 사용량의 임계값을 기반으로 경보 생성.
경보의 지표 및 조건
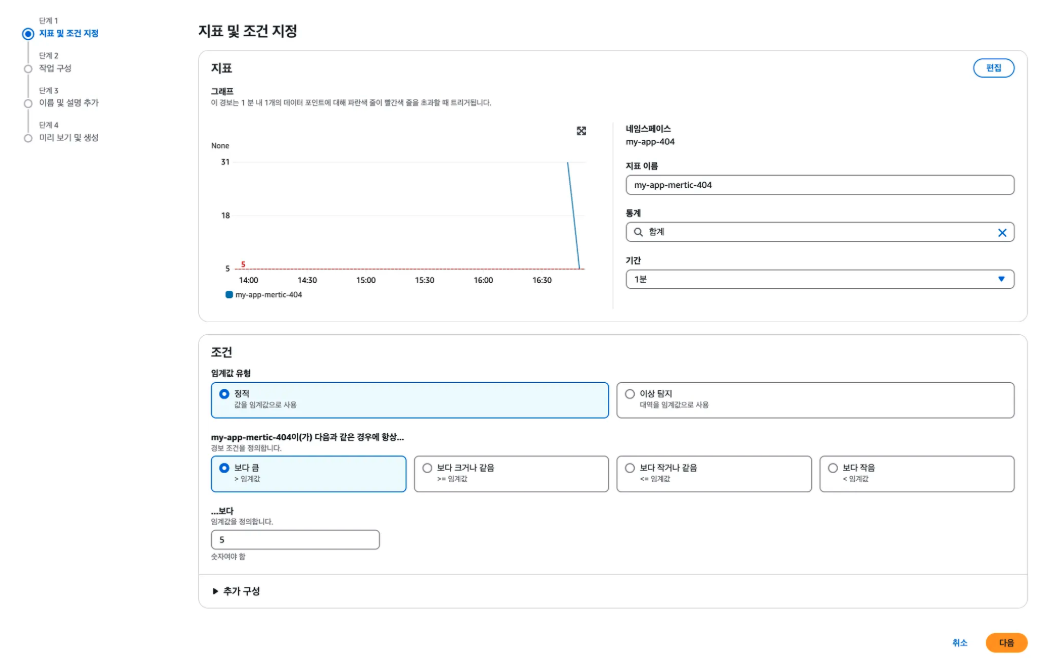
위의 사진은 특정 지표를 바탕으로 경보를 생성하는 과정이다. 예를 들어서 경보의 설정 구성 요소에 대해서 살펴보자.
지표 설정
- 네임스페이스: my-app-404
- 지표 이름: my-app-metric-404 (HTTP 404를 측정하는 커스텀 지표)
- 기간(Period): 1분 → 지표의 평가 간격으로, 1분마다 수집된 데이터로 조건을 판별한다.
- 통계: 합계(Sum) → 1분 동안 발생한 값들의 합계를 기준으로 경보를 평가한다.
조건 설정
- 임계값 유형: 정적 → 고정된 숫자를 기준으로 경보를 발생시키는 방식을 사용한다.
- 조건 설정: 보다 큼 조건 선택 → 지표 값이 임계값을 초과할 경우 경보 발생
- 임계값: 5 → 즉 1분 동안 지표의 합계가 5보다 크면 ALARM 상태로 전환된다.
경보 작업 구성
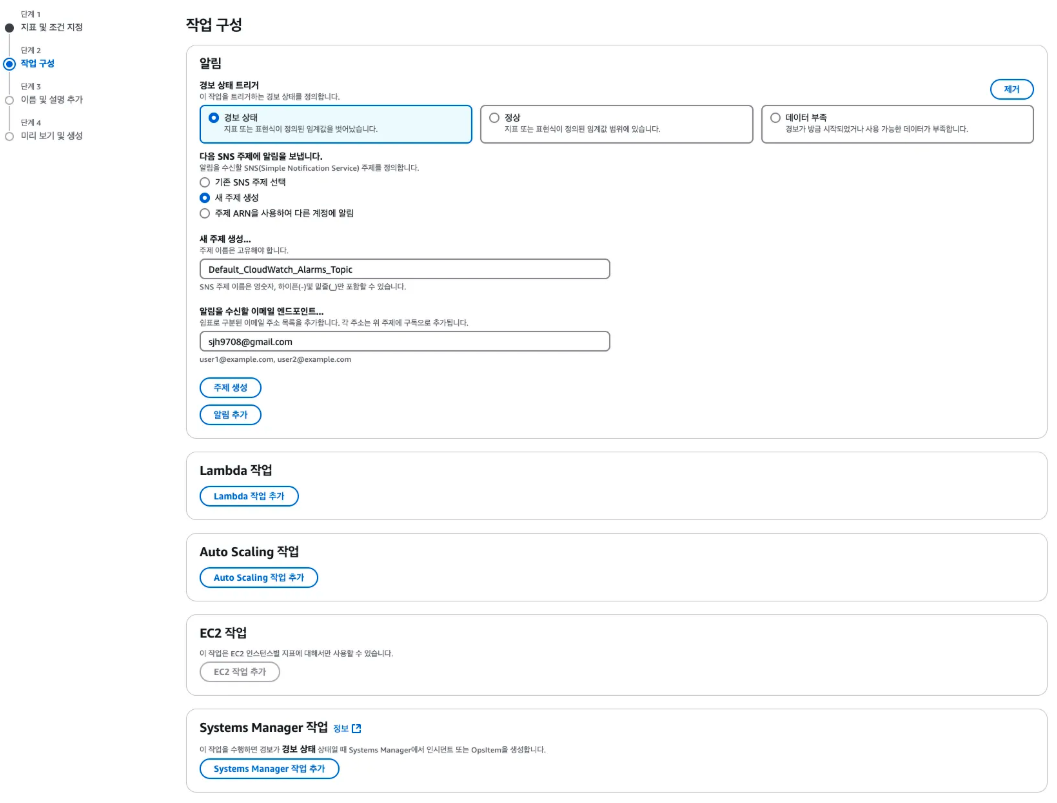
경보가 특정 상태가 되었을 때 수행할 작업을 정의할 수 있다. 주로 경보 상태(ALARM)일 때의 대응 자동화를 위해서 많이 사용된다.
위의 사진에서는 404 Error가 1분에 5번 이상 발생할 시, SNS를 이용하여 Email로 경보를 전송하는 행동을 설정하였다.
주요 작업 항목들
- SNS(Simple Notification Service) 알림 전송 : 이메일, SMS, 푸시 알림 등
- Lambda 작업 추가: Lambda 함수를 실행시켜 맞춤형 대응 작업 수행
- Auto Scaling 작업 추가: EC2 Auto Scaling 그룹의 인스턴스 조정
- EC2 작업 추가: 특정 EC2 인스턴스를 시작, 중지, 재부팅 등
- Systems Manager 작업 추가: SSM으로 등록된 인스턴스에 명령 실행 또는 OpsItem 생성
경보 상태 확인
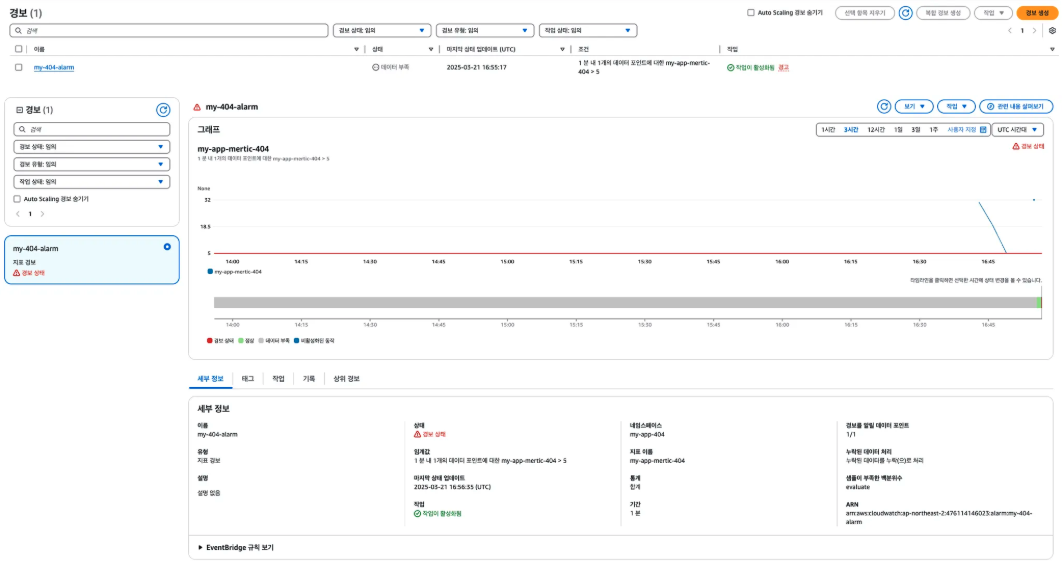
생성한 경보의 현재 상태, 지표, 조건 등을 시각적으로 확인할 수 있는 관리 페이지이다.
위의 사진을 보면, 지표의 데이터 포인트가 임계치인 5를 초과하였기 때문에 경보 상태(ALARM)으로 전환된 것을 확인할 수 있다.
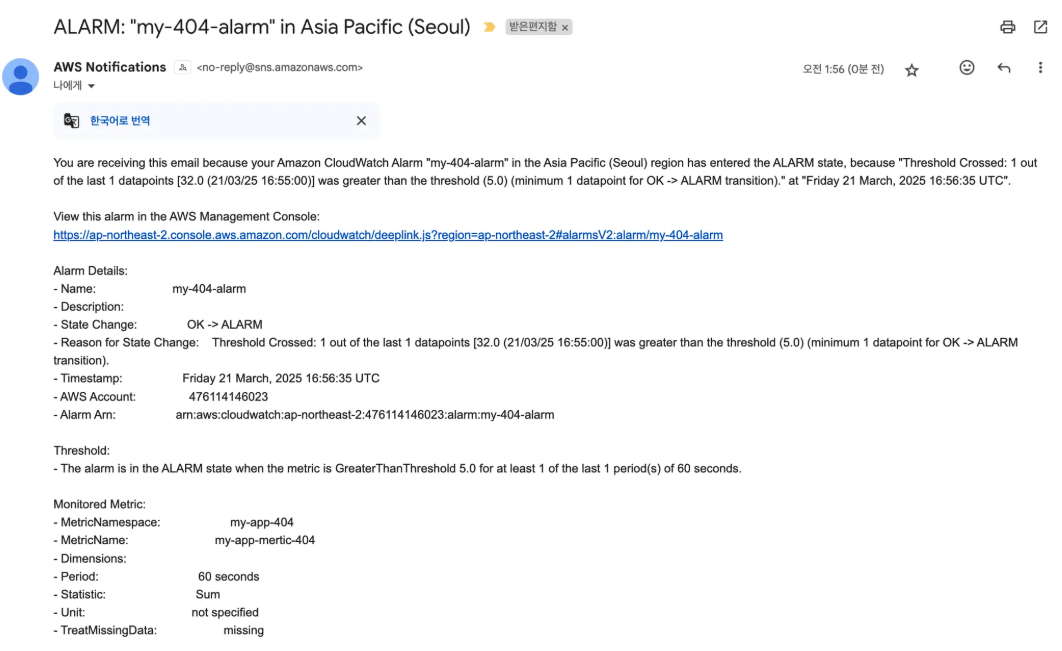
위에서 설정했듯, 경보 상태(ALARM)일 때 AWS SNS을 통해서 이메일로 경보 노티가 발송된 것을 확인할 수 있다.
References
https://docs.aws.amazon.com/
docs.aws.amazon.com
쉽게 설명하는 AWS 기초 강의 강의 | AWS 강의실 - 인프런
AWS 강의실 | , 안녕하세요. AWS 강의실입니다.AWS 공식 커뮤니티 빌더이자 2만명의 구독자를 보유한 AWS Only 강의 유튜브의 경험으로 AWS를 쉽게 알려드립니다.이 강의는AWS의 서비스 및 활용 지식을
www.inflearn.com
'Backend > AWS' 카테고리의 다른 글
| [AWS + Spring] RDS + Secrets Manager 연동하기 (0) | 2025.03.11 |
|---|---|
| [AWS] RDS : 자격 증명과 Connection (+ AWS Secrets Manager & RDS Proxy) (0) | 2025.03.10 |
| [AWS] RDS : 서비스 개요 및 프로비저닝 설정 (0) | 2025.03.10 |
| [AWS] Amazone Athena & Amazone Glue : 데이터 소스에 대한 스키마 분석 및 쿼리 수행 기초 (0) | 2025.02.19 |
| [AWS] S3 활용 : Static Hosting (정적 웹 호스팅) (0) | 2025.02.19 |








