
[딥러닝] CNN : 이미지 학습을 위한 신경망 (+ MNIST 손글씨 분류해보기)

CNN(Convolutional Neural Network, 합성곱 신경망)
CNN은 이미지 및 시각적 데이터 처리를 위해 개발된 신경망이다. CNN은 이미지의 패턴을 인식하고, 이미지 분류, 물체 인식, 얼굴 인식 등 다양한 과제에서 뛰어난 성능을 발휘한다. 현대 시각 지능 기술의 핵심적인 기술로서 자리하고 있다.
해당 포스팅에서는 다음과 같은 사항들을 알아보려고 한다.
1. 컨볼루션 연산
2. 최초의 CNN : LeNet5
- 세상에서 가장 간단한 도형 인식으로 CNN 이해하기
- LeNet5의 구조
3. 기존 DNN의 한계와 CNN의 등장 배경 및 특징
4. 다양한 CNN 기반 모델 : AlexNet, ZFNet, VGGNet, GoogleNet, ResNet
5. Tensorflow를 이용하여 LeNet5 모델 생성 및 학습을 통해 MNIST 손글씨 인식해보기
Convolution(컨볼루션)
Convolution : 이미지의 특징을 추출하거나 변환할 때 사용된다.
- 영상 스무딩 및 샤프닝 등 영상을 변환하거나 경계선 검출과 같이 특징을 추출하는 데에 사용할 수 있다.

컨볼루션 연산 과정

1. 위의 그림에서는 5x5 사이즈의 Input Image가 있다.
2. Input에 대해서 3x3 사이즈의 Convolution Filter(Kernel)를 적용하여 차례로 연산을 수행한다.
- 컨볼루션 필터 : 특정 크기의 행렬이며 이미지에서 특징(Feature)를 추출하는 데 사용된다. 커널은 입력 이미지의 부분 영역과 컨볼루션 연산을 수행하여 출력 이미지나 특징 맵(Feature Map)을 생성한다.
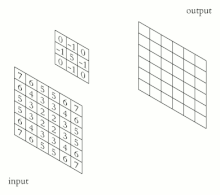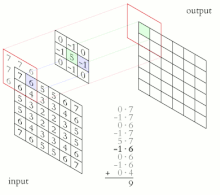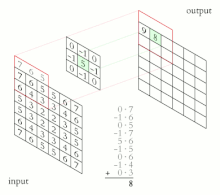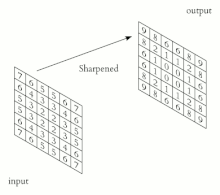
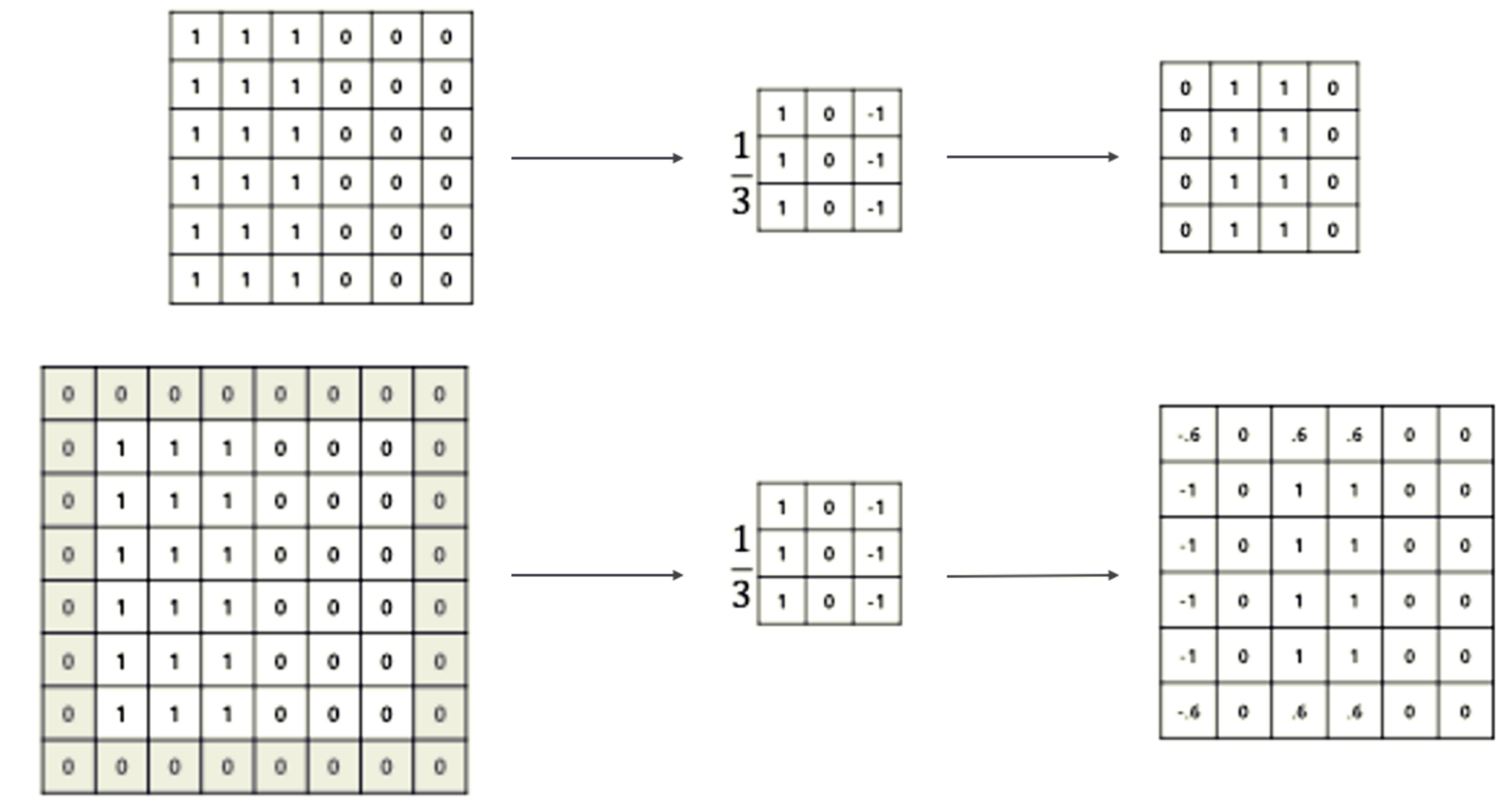
3. 입력 이미지를 \(x\), 출력 이미지를 \(y\), Kernel를 \(w\)라고 한다면 컨볼루션 연산은 다음과 같이 진행된다.
- (size = 3x3, stride = 1, padding = None)
- \(y_{11}\) = \(x_{11}w_{11}\) + \(x_{12}w_{12}\) + \(x_{13}w_{13}\) + \(x_{21}w_{21}\)+ ... + \(x_{33}w_{33}\)
- \(y_{12}\) = \(x_{12}w_{12}\) + \(x_{13}w_{13}\) + \(x_{14}w_{14}\) + \(x_{22}w_{22}\)+ ... + \(x_{34}w_{34}\)
- ...
- \(y_{33}\) = \(x_{33}w_{33}\) + \(x_{34}w_{34}\) + \(x_{35}w_{35}\) + \(x_{53}w_{53}\)+ ... + \(x_{55}w_{55}\)
4. 컨볼루션 결과로 나온 Output은 CNN에서 Feature Map으로서 활용한다.
- Feature Map(특징 맵) : 입력 이미지의 특정 특징(Feature)을 강조하여 표현하며 CNN에서는 입력 이미지에서 유용한 정보를 추출하고 이를 다음 계층으로 전달하여 점진적으로 더 복잡한 특징을 학습하는 데 중요한 역할을 한다.
<컨볼루션 연산의 수행 과정>
컨볼루션 연산의 주요 속성
Size
적용할 Convolution Filter(Kernel)의 크기, 3x3, 4x4 등
Stride
컨볼루션 커널(필터)을 입력 이미지 위에서 슬라이딩할 때, 각 단계에서 이동하는 간격이다.
스트라이드가 클수록 출력 특징 맵의 크기는 작아지고, 연산의 양도 줄어든다.
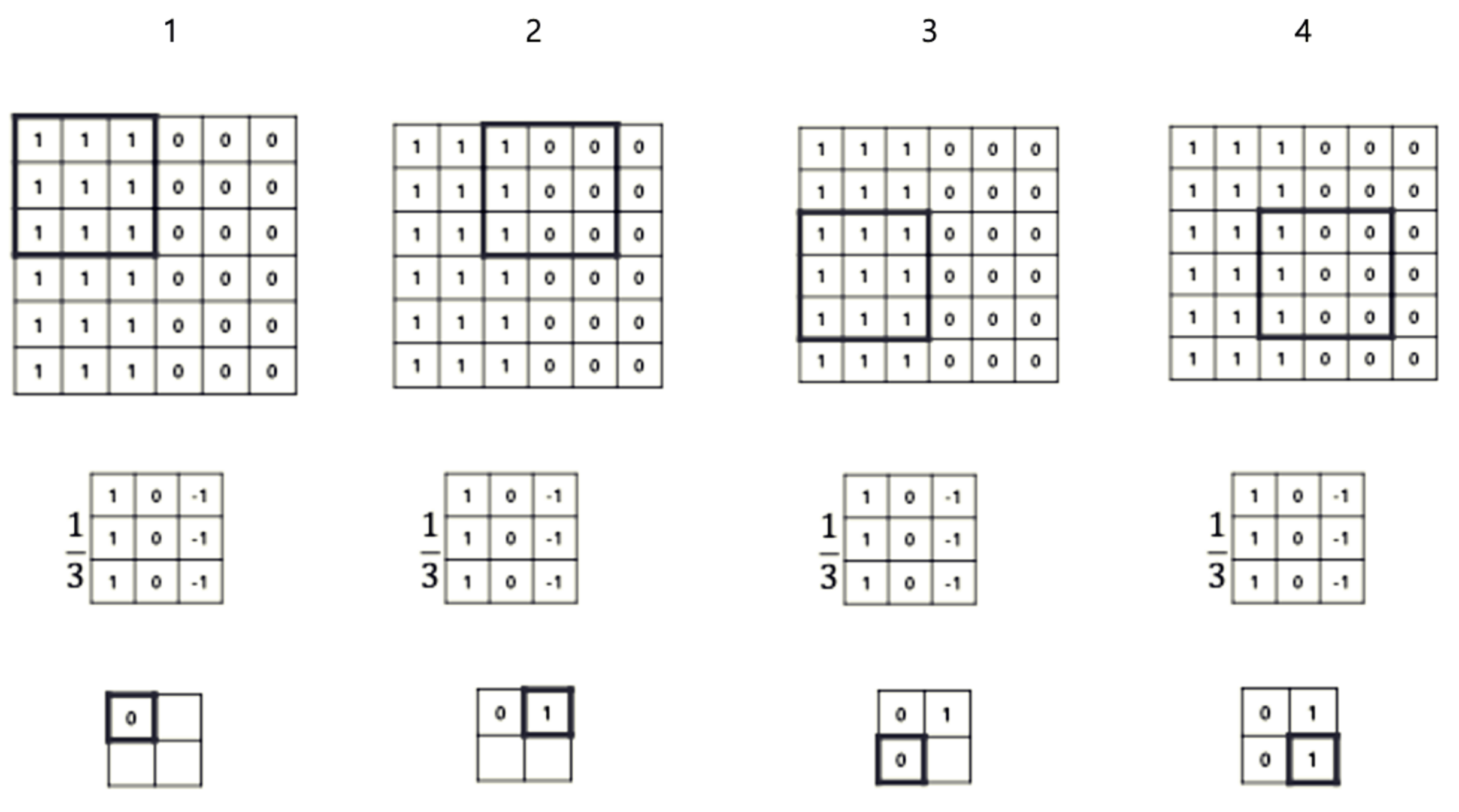
위의 그림은 Size = 3x3, Stride = 2인 컨볼루션 연산을 적용한 그림이다. Stride가 2이므로 컨볼루션이 2칸씩 띄워서 적용되는 것을 알 수 있다.
Padding
입력 이미지의 가장자리에 특정 값을 추가하여 크기를 인위적으로 늘리는 것이다.
패딩의 중요성은 경계 부분에서 정보를 잃지 않도록 보호하고, 출력 특징 맵의 크기가 원본에 비해 너무 작아지지 않도록 조절하는 역할을 한다.
위의 그림은 Size = 3x3, Stride = 1, Padding = 1(0-padding)인 컨볼루션 연산을 적용한 그림이다. 출력인 Feature Map의 크기를 유지해주는 역할을 한다는 것을 알 수 있다.
출력 이미지의 크기

출력 이미지의 크기는 Kernel Size, Stride, Padding에 따라서 다음 공식이 성립한다.
예를 들어 아래와 같은 파라미터가 주어진다면 나오는 결과는 아래와 같다.
- 입력 이미지 크기 : 5x5
- 커널 크기 : 3x3
- 스트라이드 : 2
- 패딩 : 1
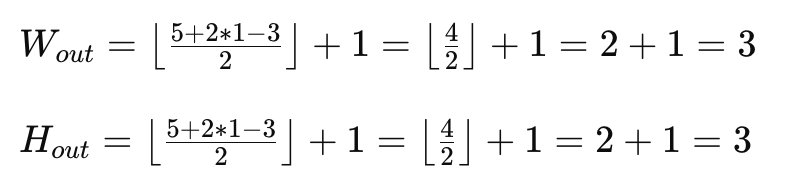
최초의 CNN : LeNet5
Yann LeCun 등이 개발한 최초의 CNN (convolutional neural network) 모델. 필기체 숫자 영상으로부터 숫자를 인식하는 데 성공하였다.
- 32x32 영상을 10개의 숫자로 분류하는 모델이다.
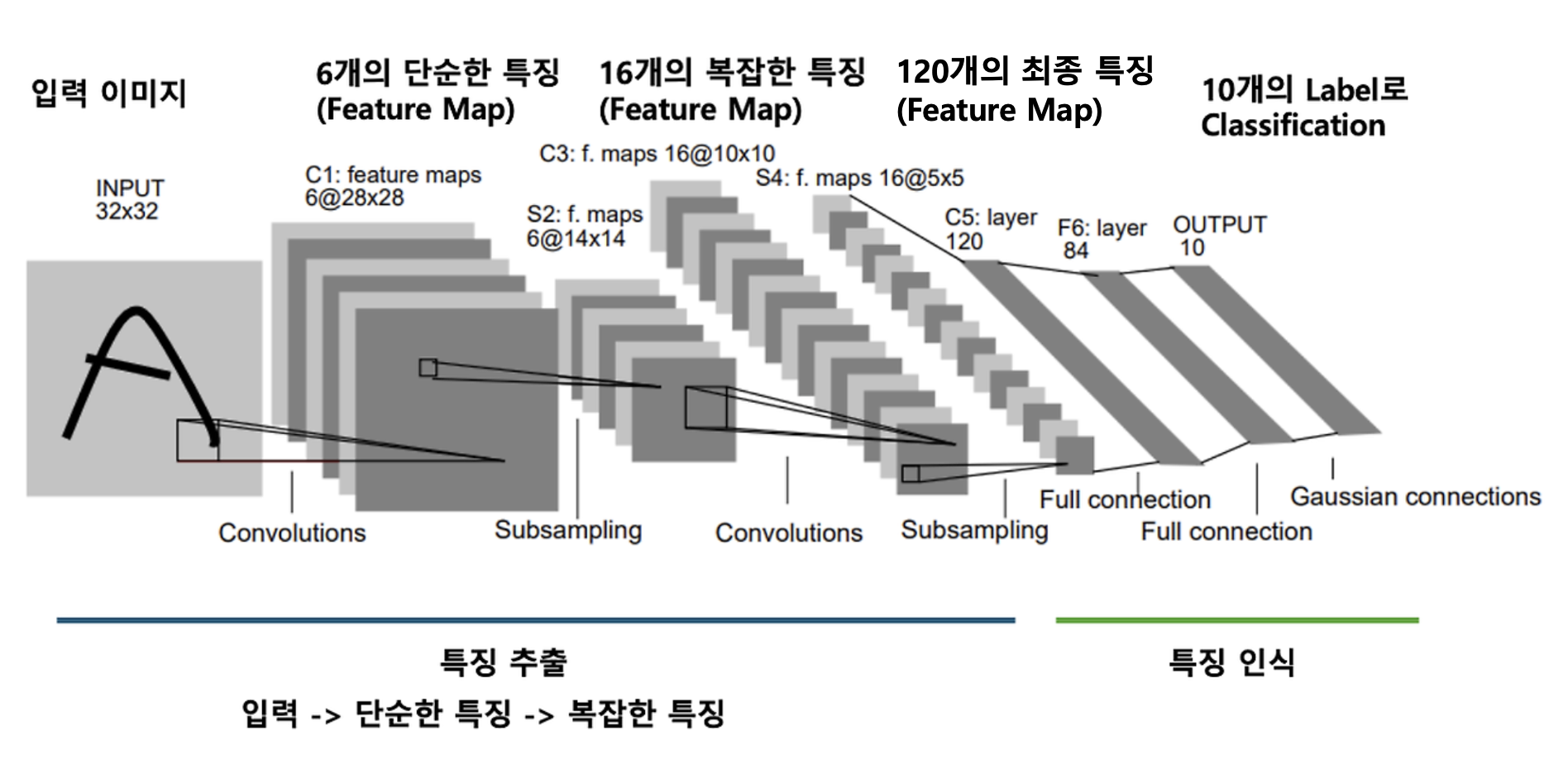
LeNet5는 특징 추출 단계(3개의 Convolution + 2개의 Subsampling Layer)와 특징 인식 단계(2개의 Fully Connected layer)로 구성되어 있다.
Convolutional Layer
- 컨볼루션 레이어는 입력 이미지에 대해 필터를 적용하여 특징들을 추출한다
- 적용한 Convolution의 수 만큼의 Feature Map이 출력으로 나온다.
- 예를 들어 수직선을 검출하는 Filter, 수평선을 검출하는 Filter 두 개의 컨볼루션을 수행하면 영상에서 수직선을 나타내는 Feature Map, 수평선을 나타내는 Feature Map이 나온다.
- 컨볼루션 필터는 노드(뉴런)의 역할을 하며 중요한 특징을 뽑아낼 수 있도록 각 필터의 가중치를 학습하는 것이 목표이다.
Subsampling(Pooling) Layer
- 컨볼루션 Layer의 출력을 다운샘플링하여 공간적인 크기를 줄인다. Feature Map을 압축한다고 생각하면 된다. 모델의 파라미터(가중치)의 양을 줄이고, 계산량을 감소시키는 역할을 한다.
- Max Pooling이나 Average Pooling과 같은 기법을 사용하여 중요한 특징을 유지하면서 공간적 크기를 줄일 수 있다.
Fully Connected Layer
- 각 특징의 조합을 학습하고 최종 출력을 생성한다.
- 이전 Layer의 출력에 대한 가중치와 편향을 학습하여 입력 데이터의 패턴을 인식한다.
예시) 가장 간단한 영상 인식 : 도형 인식하기
각각의 Layer들의 역할을 이해하기 위해서 다음과 같은 예시를 들어보겠다.
세상에서 가장 단순한 형태로 고정된 필터를 이용해서 특징을 추출하고 추출된 Feature Map을 통해 결과를 예측하는 과정을 살펴보자.
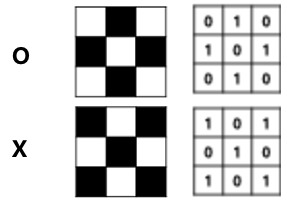
위 그림과 같이 O와 X를 인식하고 싶다고 해 보자.
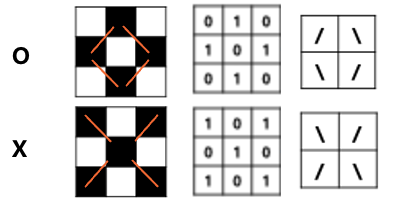
O와 X를 구분하는 가장 간단한 방법은 왼쪽 사선으로 있는 선과, 오른쪽 사선으로 있는 선이라는 특징을 추출해내는 것이다.
특징을 잘 추출할 수 있는 필터 결정하기
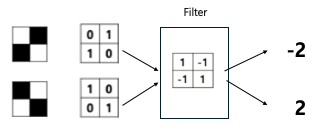
두 개의 사선을 검출할 수 있는 필터를 결정해야 한다. 위와 같은 필터를 적용하게 되면 두 개의 특징을 2와 -2로 확연히 구분하는 필터로서 역할을 할 수 있다.
필터를 결정하는 방법
- Explicit method: 사람이 적절한 필터 값을 계산하는 방식. 고전적인 방법이다.
- Implicit method: 학습을 통해서 적절한 필터 값을 얻어내는 방식. CNN에서는 Backpropagation 과정에 의해 각 필터가 중요한 특징을 잘 뽑아낼 수 있도록 갱신된다.
특징 추출 (Convolution + Pooling)
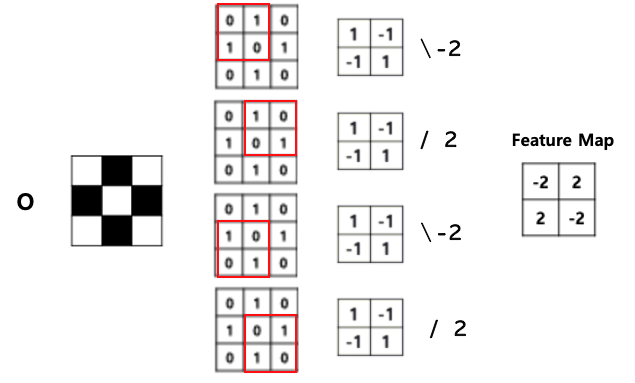
이제 Input 영상에 대해서 특징들을 추출하기 위한 컨볼루션 필터를 적용하여 연산을 수행한다.
영상은 Convolution(Feature를 추출) 과정과, Subsampling(압축, 영상의 크기가 크다면)을 통해 Feature Map을 만들어낸다.
위의 예시는 두 개의 사선이라는 간단한 특징들만 추출하면 되서 컨볼루션 필터를 1개만 적용하면 되었다.
그렇지만 수평선, 수직선 등 다양한 특징들을 추출하려면 더 많은 컨볼루션 필터가 필요하며, 타원, 사각형 등의 복잡한 특징들을 추출하려면 Convolution+Pooling Layer가 여러 개 필요해진다.
만약 각 도형들이 Input으로 주어졌다고 생각해 봤을 때 다음과 같은 형태의 Feature Map들이 나오게 될 것이다.
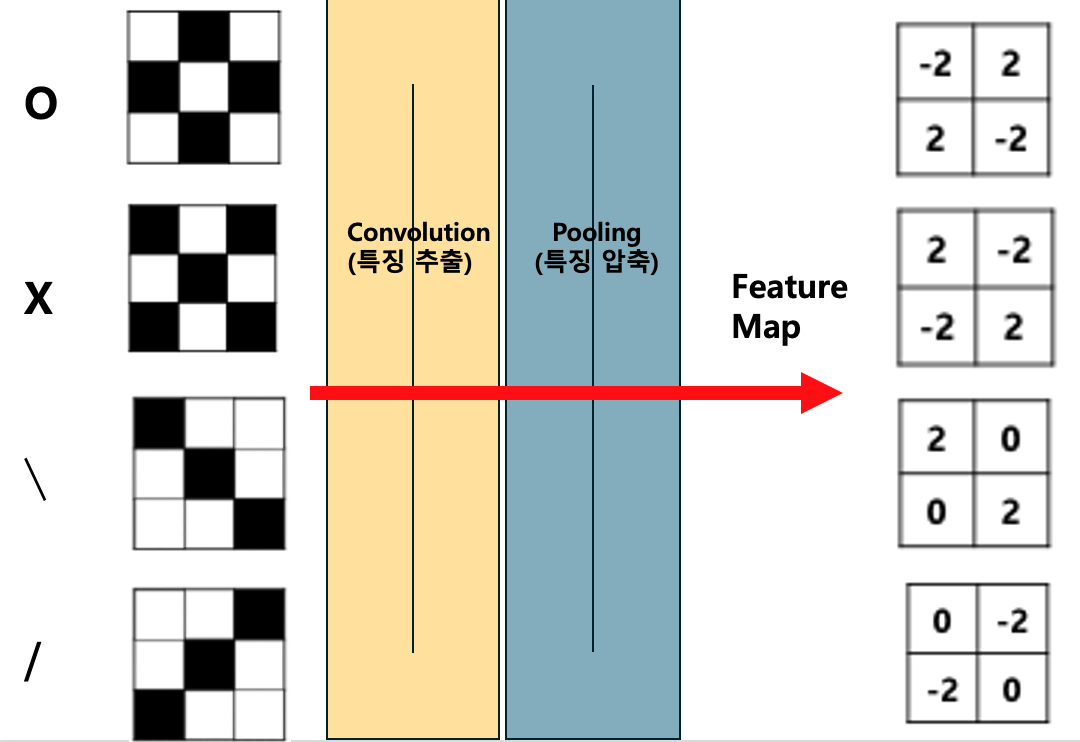
특징 인식(Fully-Connected)
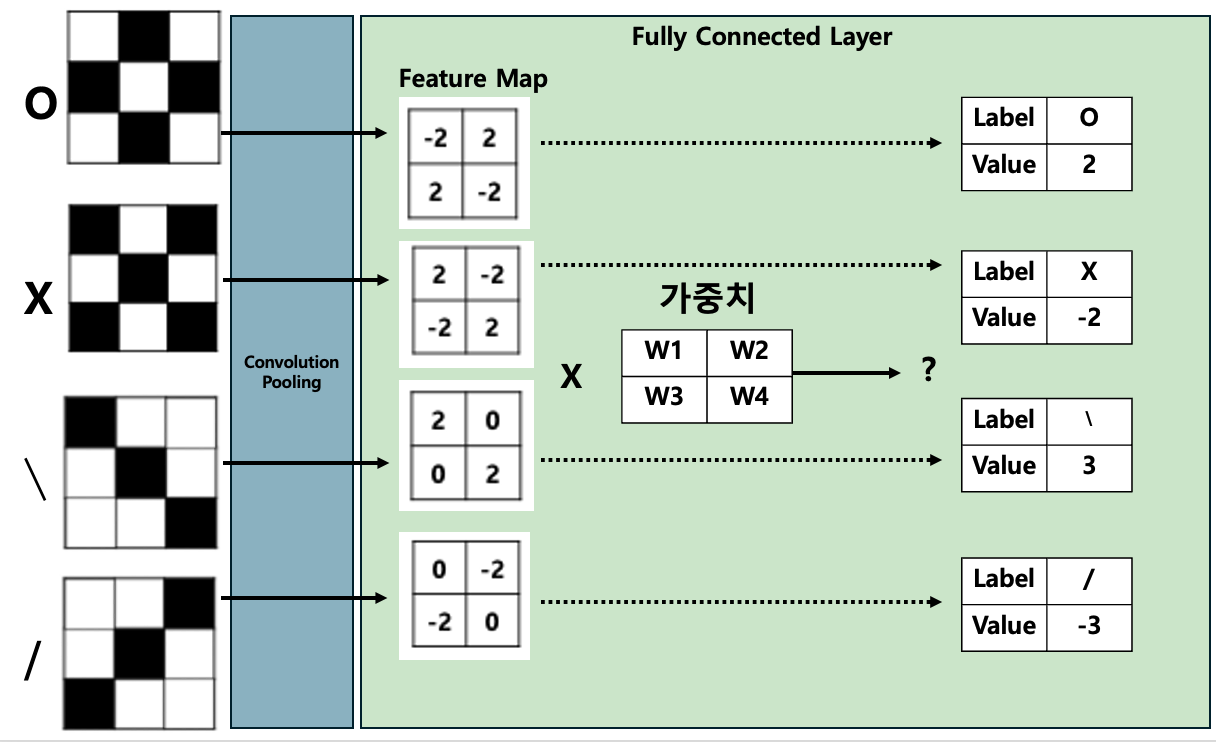
Convolution과 Pooling 과정으로 최종적으로 나온 Feature Map은 Flatten되어 1차원 벡터의 형태로 아Fully Connected Layer의 입력으로서 사용된다.
Full Connected Layer은 Feature Map에 대해서 어떤 Weignt(가중치)를 적용해야 예측에 성공할 것인가를 학습시키는 과정이다.
위의 그림에서 보면 각각의 도형들은 2, -2, 3, -3의 값이 나와야 하며, Feature Map에서 어떤 가중치를 적용해야 하는 것이 학습의 목표이다. 이 학습 과정에서 NLP와 마찬가지로 Backpropagation이 사용된다.
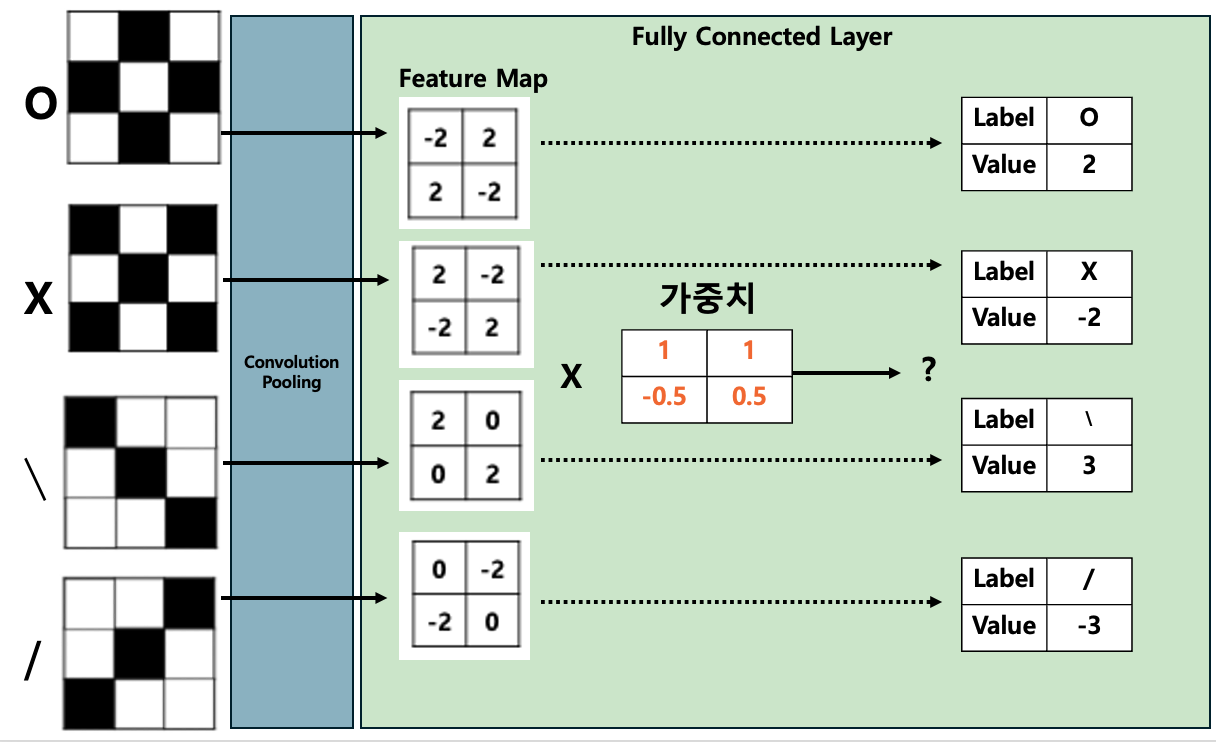
만약 다음과 같이 가중치의 학습이 완료되었다면, 입력 이미지로부터 O, X, 대각선의 예측이 성공적으로 이루어질 것이고, 성공적인 인공지능 모델의 학습이 이루어졌다고 볼 수 있다.
LeNet5 구조
이제 다시 한번 LeNet5의 구조에 대해서 살펴보자.
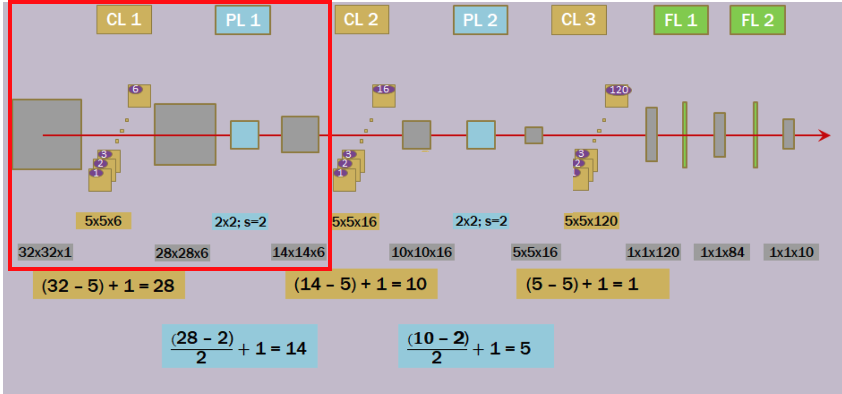
입력 영상 : LeNet5는 32x32의 Input 영상으로부터 10개의 출력으로 예측을 수행한다고 하였다.
- 입력: 32x32x1
C1 : 1번째 Convolution 연산 : 5x5 크기의 6개의 컨볼루션을 적용한다. -> 6개의 특징들에 대한 6개의 Feature Map이 생긴다.
- 입력: 32x32x1 -> 출력: 28x28x6
S1 : 1번째 Subsampling 연산 : 2x2(Stride=2) 크기의 Matrix를 적용하여 6개의 Feature Map의 크기를 압축한다.
- 입력: 28x28x6 -> 출력: 14x14x6
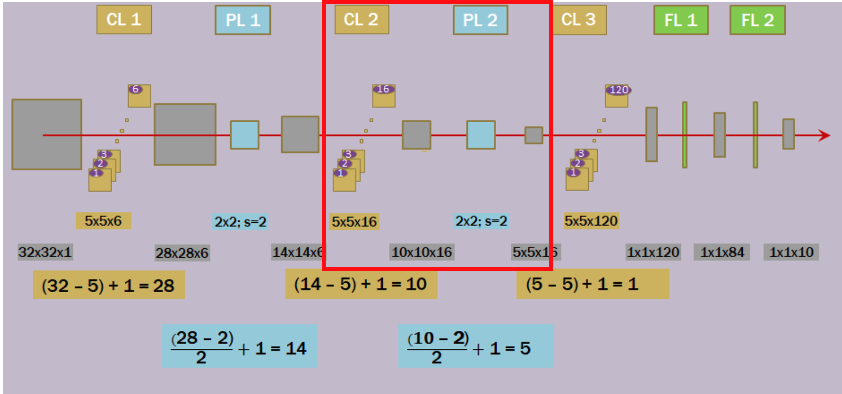
C2 : 2번째 Convolution 연산 : 5x5 크기의 16개의 컨볼루션을 적용한다. -> 6개의 Feature Map으로 부터 16개의 복잡한 특징을 추출하여 Feature Map으로 만든다.
- 입력: 14x14x6 -> 출력: 10x10x16
S2 : 2번째 Subsampling 연산 : 2x2(Stride=2) 크기의 Matrix를 적용하여 16개의 Feature Map의 크기를 압축한다.
- 입력: 10x10x16 -> 출력: 5x5x16
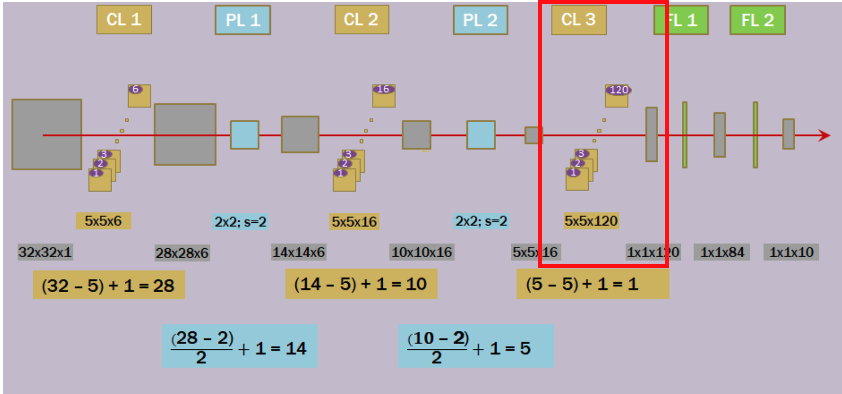
C3 : 3번째 Convolution 연산 : 5x5 크기의 120개의 컨볼루션을 적용한다. -> 16개의 Feature Map으로 부터 120개의 특징을 얻어낸다.
- 입력: 5x5x16-> 출력: 1x1x120
- 이미지로부터 추출되고 압축된 120개의 중요한 특징 벡터이며, Fully Connected Layer에서 입력 벡터로 사용하여 최종 분류 작업을 수행한다.
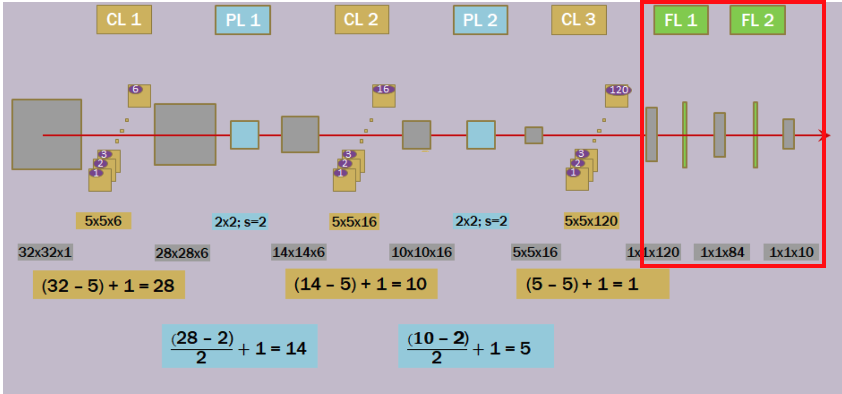
F1 : 1번째 Fully Connected Layer
- 입력: 1x1x120 -> 출력: 1x1x84
- 각 뉴런은 입력 전체에 대해 가중치를 가지고 있으며, 이는 이미지의 특징을 더 높은 차원의 특징 벡터로 변환한다. 추출된 특징들을 결합하여 더욱 추상적인 특징을 학습하는 과정이다.
F2 : 2번째 Fully Connected Layer
- 입력: 1x1x84 -> 출력: 1x1x10
- 84개의 입력을 받아 최종 출력인 10개의 Output Layer의 뉴런으로 연결한다. 다중 클래스 분류이므로 뉴런들은 각각의 클래스에 대한 확률 값을 출력하게 된다.
Backpropagation
이 과정에서 Fully Connected Layer의 뉴런의 가중치뿐만 아니라 Convolutional Layer(합성곱 층)의 필터 가중치들도 갱신되며, 더욱 중요한 특징을 잘 뽑아낼 수 있도록 학습된다.
CNN의 등장 배경과 특징
등장 배경
기존의 Deep Nerual Network를 영상에서 사용하기에 다음과 같은 문제점이 있었다.
1. 매개변수의 개수
- 문제: 모든 입력 노드가 다음 계층의 모든 노드와 연결되어 있어, 이미지와 같은 고차원 데이터를 다룰 때 매우 많은 수의 매개변수가 필요 -> 계산 비용 증가 & 과적합(Overfitting) 유발
- 입력 이미지가 1280 x 854 사이즈의 컬러 이미지(x3)라면, 입력 사이즈는 3,279,360이다.
- 만약 다음 Hidden Layer의 노드가 250개라면 Weight의 개수로 819,840,000개가 필요하다.
- CNN: 공유 가중치와 희소 연결을 통해 해결
2. 공간적 구조의 무시
- 문제: 이미지를 일렬로 펼친 벡터로 처리하게 되면 이로 인해 이미지의 픽셀 사이의 공간적 관계가 무시된다. -> 주요한 특징을 잡아낼 수 없다.
- CNN: 각 필터는 이미지의 지역적인 패턴(특징)을 감지하고, 이러한 패턴의 정보가 다음 계층으로 전달
3. 변형에 대한 적응성 부족
- 문제: 이미지의 작은 변형(이동, 회전, 크기 조정 등)에 대해 민감하게 반응 → 변형된 이미지를 완전히 새로운 이미지로 인식할 수 있음
- CNN: 풀링(Pooling) 계층을 사용하여 이 문제를 해결
CNN의 특징
1. 희소 연결 성질
- 각 뉴런이 입력의 일부와만 연결된다는 것. 전통적인 Fully-connected에서는 각 뉴런이 이전 Layer의 모든 뉴런과 연결되지만, CNN의 Convolution Layer에서는 각 뉴런이 입력의 작은 부분(필터의 크기 만큼)과만 연결된다.
- 계산 효율성을 높인다. 파라미터 수를 줄여 과적합(Overfitting)을 방지한다. 지역적(국소적)인 특징을 잘 감지할 수 있다.
2. 공유 가중치 (파라미터 공유 성질)
- 동일한 커널(가중치 행렬)이 입력 이미지의 여러 위치에 적용된다.
- 학습할 가중치(파라미터)의 수를 크게 줄여준다.
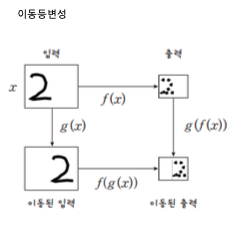
3. 이동등변성
- 입력이 이동되었을 때, 출력이 동일하게 이동하는 성질
- CNN이 이미지 내에서 동일한 패턴을 인식하는 데 유리하게 만든다.
- 예를 들어 고양이의 얼굴이 이미지의 어느 위치에 있든 CNN은 동일한 필터로 고양이 얼굴을 인식할 수 있다.
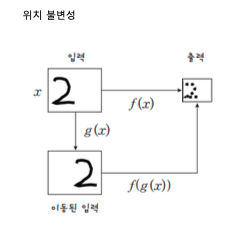
4. 위치불변성
- 이미지의 특정 패턴이 위치를 바꿔도 네트워크가 해당 패턴을 인식할 수 있는 능력.
- CNN에서는 Pooling Layer을 통해 달성된다.
- Pooling은 입력의 공간적 크기를 줄이면서 중요한 특징을 추출하고 높은 수준의 추상적 특징으로 변환한다.
- 이는 이미지의 세부적인 위치 변화에 대해 강건한 특성을 갖게 된다.
CNN 기반으로 해결 가능한 작업 분류
1. Image Classification (이미지 분류)
2. Object Detection (물체 탐지)
3. Semantic Segmentation (의미 분할)
4. Instance Segmentation (인스턴스 분할)
5. Object Tracking (물체 추적)
6. Pose Estimation (자세 추정)
7. Image Captioning (이미지 캡션 생성)
8. OCR (Optical Character Recognition, 광학 문자 인식)
9. Image Generation (이미지 생성)
10. Image Restoration (이미지 복원)
다양한 CNN 기반 모델
AlexNet
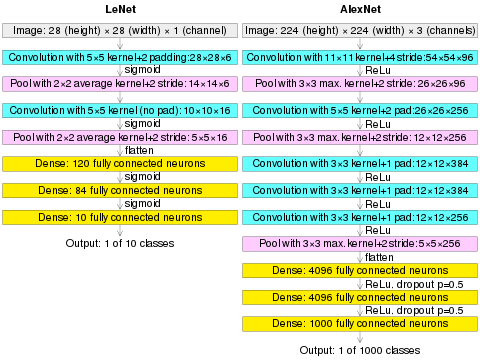
1. AlexNet의 등장 배경: 이미지넷 챌린지(ILSVRC)에서 2012년 우승을 차지하며 딥러닝의 가능성을 널리 알림
2. 특징
- 5개의 Convolution 레이어와 3개의 Fully Connected Layer로 구성
- ReLU 활성화 함수 사용, Overfitting 방지를 위한 Dropout과 데이터 증강 기법 도입
- 2개의 GPU를 병렬처리를 통해 학습, 로컬 반응 정규화(Local Response Normalization, LRN) 사용
3. 구조
- Inpuyt Layer : 227x227x3 크기의 입력
- Convolution Layer : 다양한 커널 크기와 스트라이드를 사용하여 특징 추출
- Pooling Layer : 최대 풀링을 사용하여 차원 축소
- Fully-connected Layer: 4096개 뉴런을 포함하고 마지막 분류를 위해 1000개 클래스 출력
4. 업적: 기존 모델 대비 획기적인 성능 향상, 딥러닝의 상용화 촉진
ZFNet
AlexNet의 아키텍처와 차이점
- CONV3, CONV4, CONV5의 필터 개수 변경
- 모델을 GTX 580 GPU 하나로 학습하기 위해 두 그룹을 합침
- CONV1 layer에서 11x11, 4개 → 7x7, 2개 사용
Convolution layer 시각화

- 첫 번째, 두 번째 Layer : Edge와 색 인식
- 세 번째 Layer: 비슷한 질감을 갖는 복잡한 형태인식 (위치불변성에 따라 객체가 이동해도 같은 Convolution Filter로 인식)
- 네 번째 Layer: 사물이나 개체의 일부 특징을 인식
- 다섯 번째 Layer: 사물이나 개체의 위치 및 자세 변화를 포함한 전체적 모습 인식
VGGNet
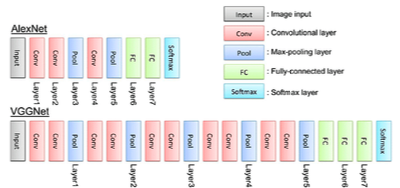
ILSVRC 2014 대회에서 2위 수상: “Very Deep Convolutional Networks for Large-Scale Image Recognition”
작은 필터를 사용하고 깊은 신경망을 사용, 당시 우승한 GoogleNet보다 성능이 조금 못 미치지만 모델 구조가 단순하여 아직까지도 많이 사용된다.
ResNet
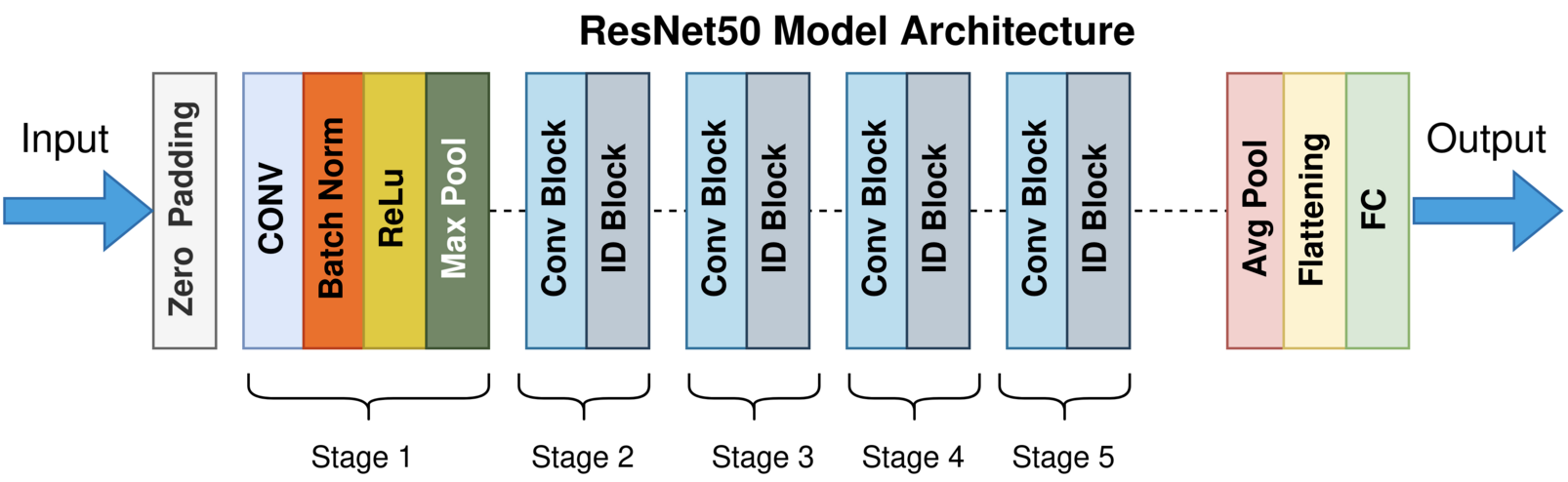
Microsoft에서 개발, 처음으로 ILSVRC에서 인간의 인지 능력인 5.1% 보다 낮은 3.57% 오류 달성
인공 신경망의 Depth가 깊어질 수록 훈련은 어렵다. 학습을 용이하게 하기 위해서 Residual Learning Framework를 제안하였다.
ImageNet : 152개의 깊은 Layers를 사용하는 ResNet 기반의 모델이다.
<함께 보기> ResNet Layer 분석과 ResNet 모델로 동물 이미지 분류하기(CIFAR)
https://sjh9708.tistory.com/224
[딥러닝] CNN : ResNet 모델로 동물 이미지 분류하기(CIFAR 이미지셋)
이전 포스팅에서 우리는 CNN의 개념과, LeNet5부터 시작해서 다양한 CNN 모델들을 알아보고, LeNet5 모델을 학습시켜서 MNIST 손글씨를 분류해보는 작업까지 해 보았었다.https://sjh9708.tistory.com/223 [딥러
sjh9708.tistory.com
GoogleNet
2014년 ILSVRC에서 우승을 차지한 Deep Neural Network 아키텍쳐이다.
인공 신경망에서 Depth와 Width를 증가시키면서도 동시에 컴퓨팅 자원을 일정하게 유지하며. 사용하는 모델을 개발하려고 했다.
고전적인 컨볼루션 네트워크를 발전시켜 더 깊고, 더 넓으면서도 계산 효율성을 향상시킨 첫 번째 모델 중 하나이다.
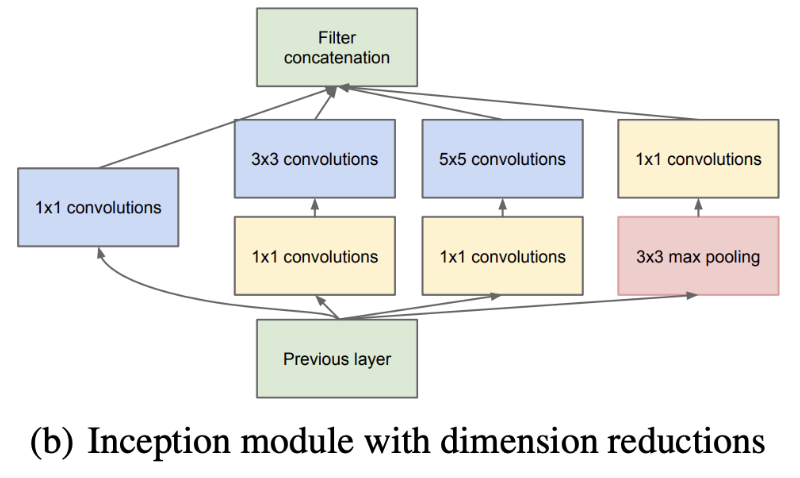
- Deep Convolutional Neural Network를 기반으로 하는 Inception 구조를 사용하였다.
- 최적화 : Habbian 원리와 다중 스케일 Processing을 기반으로 설계를 진행, 컴퓨팅 자원을 효율적으로 활용할 수 있도록 함
- Auxiliary classifiers: 가중치를 학습하는 역전파 과정 중 gradient가 점점 작아져서 0이 되는 문제가 발생, 이를 극복하기 위해 중간에 두개의 보조 분류기 사용
- 계산의 효율성 : 5x5 Filter 대신 3x3 Filter를 2번 사용
Tensorflow로 MNIST 손글씨 인식하기 (LeNet5)
지금까지 학습한 CNN 지식을 바탕으로 이번엔 직접 Tensorflow를 이용해서 LeNet5 모델을 만들어보고 MNIST 손글씨 데이터를 학습시키는 과정을 만들어보자.
![]()
from IPython.core.display import display, HTML
display(HTML("<style>.container {width:90% !important;}</style>"))
from google.colab import drive
drive.mount('/content/drive')
import matplotlib.pyplot as plt
import numpy as np
import os
%load_ext autoreload
%autoreload 2
os.chdir('drive/MyDrive/DL2024_201810776/week10')
Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).
from google.colab import drive
drive.mount('/content/drive')
Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).
MNIST 데이터 로드 및 전처리¶
import tensorflow as tf
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout, Layer, AveragePooling2D, Input, BatchNormalization, ReLU, Add, GlobalAveragePooling2D
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
# 데이터 로드 및 전처리
(x_train, y_train), (x_test, y_test) = mnist.load_data()
print(x_train.shape)
# 28x28 사이즈의 이미지 -> Train/Test Set으로 분리
x_train = x_train.reshape(-1, 28, 28, 1).astype('float32') / 255 # 0~255 정규화
x_test = x_test.reshape(-1, 28, 28, 1).astype('float32') / 255
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
(60000, 28, 28)
plt.imshow(x_test[0], cmap='gray')
plt.show()

y_test[0]
array([0., 0., 0., 0., 0., 0., 0., 1., 0., 0.], dtype=float32)
CNN 모델 생성¶
- MNIST 손글씨 이미지 데이터는 28x28이다. 따라서 LeNet5의 Input이 32x32이기 때문에 처음에는 패딩을 적용해준다.
- LeNet5의 구성과 같이 C1, S1, C2, S2, C3, F1, F2의 Layer를 적용해준다.
- 입출력 차원에 유의한다.
# 모델 생성
model = Sequential([
# C1 : Convolution Layer
# Input : 28X28 * 1
# 커널 사이즈 : 5X5 * 6
# Output : 28X28 * 6
Conv2D(6, kernel_size=(5, 5), strides=(1,1), activation='relu', input_shape=(28, 28, 1), padding='same'),
# S1 : Subsampling (Pooling)
# Input : 28X28 * 6
# Output : 14X14 * 6
AveragePooling2D(pool_size=(2,2), strides=(2,2)),
# C2 : Convolution Layer
# Input : 14X14 * 6
# 커널 사이즈 : 5X5 * 16
# Output : 10X10 * 16
Conv2D(16, kernel_size=(5, 5), strides=(1,1), activation='relu', padding='valid'),
# S2 : Subsampling (Pooling)
# Input : 10X10 * 16
# Output : 5X5 * 16
AveragePooling2D(pool_size=(2,2), strides=(2,2)),
# C3 : Convolution Layer
# Input : 5X5 * 16
# 커널 사이즈 : 5X5 * 120
# Output : 1X1 * 120
Conv2D(120, kernel_size=(5, 5), strides=(1,1), activation='relu', padding='valid'),
Flatten(), # 합성곱(Convolution)과 풀링(Pooling) 레이어를 거친 후에 나오는 다차원의 특징 맵을 1차원으로 변환(Flatten)하여 Fully Connected Layer에 연결
# F1 : Fully Connected Layer
# Input : 1X1 * 120
# Output : 1X1 * 84
Dense(84, activation='relu'),
# F2 : Fully Connected Layer
# Input : 1X1 * 84
# Output : 1X1 * 10
Dense(10, activation='softmax') #10개의 카테고리(숫자 0~9)에 대한 뉴런으로 현재 이미지가 각각의 숫자일 확률이 출력으로 나온다.
])
model.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_3 (Conv2D) (None, 28, 28, 6) 156
average_pooling2d_2 (Avera (None, 14, 14, 6) 0
gePooling2D)
conv2d_4 (Conv2D) (None, 10, 10, 16) 2416
average_pooling2d_3 (Avera (None, 5, 5, 16) 0
gePooling2D)
conv2d_5 (Conv2D) (None, 1, 1, 120) 48120
flatten_1 (Flatten) (None, 120) 0
dense_2 (Dense) (None, 84) 10164
dense_3 (Dense) (None, 10) 850
=================================================================
Total params: 61706 (241.04 KB)
Trainable params: 61706 (241.04 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
모델 학습¶
- 다중 카테고리 분류이므로 Categorical Cross Entropy를 Loss로 사용한다
- Optimizer로는 ADAM을 사용한다.
# 학습
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(x_train, y_train, epochs=50, batch_size=128, validation_split=0.1)
Epoch 1/50 422/422 [==============================] - 4s 5ms/step - loss: 0.1007 - accuracy: 0.9681 - val_loss: 0.0830 - val_accuracy: 0.9747 Epoch 2/50 422/422 [==============================] - 3s 6ms/step - loss: 0.0694 - accuracy: 0.9788 - val_loss: 0.0558 - val_accuracy: 0.9848 Epoch 3/50 422/422 [==============================] - 3s 7ms/step - loss: 0.0567 - accuracy: 0.9820 - val_loss: 0.0549 - val_accuracy: 0.9835 Epoch 4/50 422/422 [==============================] - 3s 7ms/step - loss: 0.0477 - accuracy: 0.9848 - val_loss: 0.0545 - val_accuracy: 0.9845 Epoch 5/50 422/422 [==============================] - 3s 7ms/step - loss: 0.0403 - accuracy: 0.9869 - val_loss: 0.0441 - val_accuracy: 0.9892 Epoch 6/50 422/422 [==============================] - 2s 5ms/step - loss: 0.0348 - accuracy: 0.9887 - val_loss: 0.0501 - val_accuracy: 0.9875 Epoch 7/50 422/422 [==============================] - 3s 6ms/step - loss: 0.0301 - accuracy: 0.9901 - val_loss: 0.0485 - val_accuracy: 0.9853 Epoch 8/50 422/422 [==============================] - 3s 7ms/step - loss: 0.0273 - accuracy: 0.9915 - val_loss: 0.0422 - val_accuracy: 0.9893 Epoch 9/50 422/422 [==============================] - 2s 5ms/step - loss: 0.0231 - accuracy: 0.9922 - val_loss: 0.0497 - val_accuracy: 0.9865 Epoch 10/50 422/422 [==============================] - 2s 5ms/step - loss: 0.0214 - accuracy: 0.9927 - val_loss: 0.0411 - val_accuracy: 0.9883 Epoch 11/50 422/422 [==============================] - 2s 5ms/step - loss: 0.0190 - accuracy: 0.9941 - val_loss: 0.0424 - val_accuracy: 0.9905 Epoch 12/50 422/422 [==============================] - 2s 5ms/step - loss: 0.0172 - accuracy: 0.9945 - val_loss: 0.0462 - val_accuracy: 0.9877 Epoch 13/50 422/422 [==============================] - 2s 6ms/step - loss: 0.0156 - accuracy: 0.9950 - val_loss: 0.0449 - val_accuracy: 0.9897 Epoch 14/50 422/422 [==============================] - 3s 7ms/step - loss: 0.0137 - accuracy: 0.9954 - val_loss: 0.0445 - val_accuracy: 0.9895 Epoch 15/50 422/422 [==============================] - 2s 6ms/step - loss: 0.0142 - accuracy: 0.9953 - val_loss: 0.0387 - val_accuracy: 0.9897 Epoch 16/50 422/422 [==============================] - 2s 5ms/step - loss: 0.0121 - accuracy: 0.9957 - val_loss: 0.0450 - val_accuracy: 0.9893 Epoch 17/50 422/422 [==============================] - 2s 5ms/step - loss: 0.0121 - accuracy: 0.9960 - val_loss: 0.0440 - val_accuracy: 0.9880 Epoch 18/50 422/422 [==============================] - 2s 5ms/step - loss: 0.0095 - accuracy: 0.9969 - val_loss: 0.0430 - val_accuracy: 0.9903 Epoch 19/50 422/422 [==============================] - 3s 6ms/step - loss: 0.0081 - accuracy: 0.9973 - val_loss: 0.0519 - val_accuracy: 0.9893 Epoch 20/50 422/422 [==============================] - 3s 7ms/step - loss: 0.0109 - accuracy: 0.9961 - val_loss: 0.0519 - val_accuracy: 0.9877 Epoch 21/50 422/422 [==============================] - 2s 5ms/step - loss: 0.0087 - accuracy: 0.9970 - val_loss: 0.0387 - val_accuracy: 0.9907 Epoch 22/50 422/422 [==============================] - 2s 5ms/step - loss: 0.0059 - accuracy: 0.9981 - val_loss: 0.0602 - val_accuracy: 0.9872 Epoch 23/50 422/422 [==============================] - 2s 5ms/step - loss: 0.0104 - accuracy: 0.9964 - val_loss: 0.0489 - val_accuracy: 0.9897 Epoch 24/50 422/422 [==============================] - 2s 5ms/step - loss: 0.0072 - accuracy: 0.9977 - val_loss: 0.0537 - val_accuracy: 0.9883 Epoch 25/50 422/422 [==============================] - 2s 6ms/step - loss: 0.0045 - accuracy: 0.9986 - val_loss: 0.0516 - val_accuracy: 0.9898 Epoch 26/50 422/422 [==============================] - 3s 7ms/step - loss: 0.0069 - accuracy: 0.9975 - val_loss: 0.0539 - val_accuracy: 0.9883 Epoch 27/50 422/422 [==============================] - 2s 5ms/step - loss: 0.0060 - accuracy: 0.9979 - val_loss: 0.0527 - val_accuracy: 0.9880 Epoch 28/50 422/422 [==============================] - 2s 5ms/step - loss: 0.0070 - accuracy: 0.9977 - val_loss: 0.0497 - val_accuracy: 0.9900 Epoch 29/50 422/422 [==============================] - 2s 5ms/step - loss: 0.0064 - accuracy: 0.9978 - val_loss: 0.0565 - val_accuracy: 0.9882 Epoch 30/50 422/422 [==============================] - 2s 5ms/step - loss: 0.0042 - accuracy: 0.9985 - val_loss: 0.0580 - val_accuracy: 0.9892 Epoch 31/50 422/422 [==============================] - 2s 5ms/step - loss: 0.0053 - accuracy: 0.9981 - val_loss: 0.0462 - val_accuracy: 0.9907 Epoch 32/50 422/422 [==============================] - 3s 7ms/step - loss: 0.0036 - accuracy: 0.9989 - val_loss: 0.0517 - val_accuracy: 0.9900 Epoch 33/50 422/422 [==============================] - 3s 8ms/step - loss: 0.0044 - accuracy: 0.9986 - val_loss: 0.0692 - val_accuracy: 0.9875 Epoch 34/50 422/422 [==============================] - 2s 5ms/step - loss: 0.0065 - accuracy: 0.9978 - val_loss: 0.0543 - val_accuracy: 0.9905 Epoch 35/50 422/422 [==============================] - 2s 5ms/step - loss: 0.0044 - accuracy: 0.9985 - val_loss: 0.0552 - val_accuracy: 0.9898 Epoch 36/50 422/422 [==============================] - 2s 5ms/step - loss: 0.0049 - accuracy: 0.9983 - val_loss: 0.0449 - val_accuracy: 0.9907 Epoch 37/50 422/422 [==============================] - 2s 5ms/step - loss: 0.0032 - accuracy: 0.9991 - val_loss: 0.0555 - val_accuracy: 0.9897 Epoch 38/50 422/422 [==============================] - 3s 7ms/step - loss: 0.0027 - accuracy: 0.9990 - val_loss: 0.0512 - val_accuracy: 0.9917 Epoch 39/50 422/422 [==============================] - 2s 6ms/step - loss: 0.0042 - accuracy: 0.9987 - val_loss: 0.0580 - val_accuracy: 0.9893 Epoch 40/50 422/422 [==============================] - 2s 5ms/step - loss: 0.0033 - accuracy: 0.9989 - val_loss: 0.0473 - val_accuracy: 0.9920 Epoch 41/50 422/422 [==============================] - 2s 5ms/step - loss: 0.0040 - accuracy: 0.9986 - val_loss: 0.0646 - val_accuracy: 0.9888 Epoch 42/50 422/422 [==============================] - 2s 5ms/step - loss: 0.0061 - accuracy: 0.9981 - val_loss: 0.0518 - val_accuracy: 0.9908 Epoch 43/50 422/422 [==============================] - 2s 5ms/step - loss: 0.0032 - accuracy: 0.9989 - val_loss: 0.0534 - val_accuracy: 0.9907 Epoch 44/50 422/422 [==============================] - 3s 6ms/step - loss: 0.0012 - accuracy: 0.9996 - val_loss: 0.0518 - val_accuracy: 0.9915 Epoch 45/50 422/422 [==============================] - 3s 6ms/step - loss: 0.0011 - accuracy: 0.9997 - val_loss: 0.0564 - val_accuracy: 0.9902 Epoch 46/50 422/422 [==============================] - 2s 5ms/step - loss: 0.0061 - accuracy: 0.9982 - val_loss: 0.0685 - val_accuracy: 0.9883 Epoch 47/50 422/422 [==============================] - 2s 5ms/step - loss: 0.0036 - accuracy: 0.9989 - val_loss: 0.0663 - val_accuracy: 0.9908 Epoch 48/50 422/422 [==============================] - 2s 5ms/step - loss: 0.0020 - accuracy: 0.9994 - val_loss: 0.0572 - val_accuracy: 0.9910 Epoch 49/50 422/422 [==============================] - 2s 5ms/step - loss: 0.0043 - accuracy: 0.9986 - val_loss: 0.0561 - val_accuracy: 0.9905 Epoch 50/50 422/422 [==============================] - 2s 5ms/step - loss: 0.0035 - accuracy: 0.9988 - val_loss: 0.0560 - val_accuracy: 0.9897 313/313 [==============================] - 1s 3ms/step
Test Set에 대한 예측 및 모델 평가¶
# 예측
y_pred = model.predict(x_test)
y_pred = np.array(y_pred)
for idx in range(10):
plt.title(str(np.argmax(y_pred[idx])))
plt.imshow(x_test[idx], cmap='gray')
plt.show()
313/313 [==============================] - 1s 2ms/step










from sklearn.metrics import accuracy_score
accuracy = accuracy_score(np.argmax(y_test, axis=1), np.argmax(y_pred, axis=1))
accuracy
0.988
해당 포스팅의 내용은 "상명대학교 민경하 교수님 "인공지능" 수업, 상명대학교 김승현 교수님 "딥러닝"수업을 기반으로 작성하였으며, 포스팅 자료는 해당 내용을 기반으로 재구성하여 만들어 사용하였습니다.
'Data Science > 머신러닝 & 딥러닝' 카테고리의 다른 글
| [딥러닝] 기억하는 신경망 : RNN, 그리고 개선 모델 (LSTM, GRU) (0) | 2024.06.08 |
|---|---|
| [딥러닝] CNN : ResNet 모델로 동물 이미지 분류하기(CIFAR 이미지셋) (0) | 2024.06.08 |
| [딥러닝] 심층학습 시작 : 인공 신경망과 MLP (+ 신경망 모델 만들어보기) (1) | 2024.06.08 |
| [머신러닝] 앙상블 모델 : Boosting / Stacking 적용해보기 (0) | 2023.08.30 |
| [머신러닝] 앙상블 모델 : Voting / Bagging / Random Forest 적용해보기 (0) | 2023.08.30 |








