

[CS] P2P(Peer to Peer)

Client-Server
- Reliable하고 잘 알려져 있으며 강력함.
- Client가 증가할 수록 Server의 수요가 증가한다.
- Scalability 달성이 어려움, SPoF
P2P (Peer to Peer)
분산된 리소스를 사용하는 시스템 및 애플리케이션 클래스.
시스템 간의 직접적인 교환을 통해 리소스와 서비스 공유. 리소스에는 컴퓨팅 자원, 데이터 및 스토리지, 네트워크, State가 포함된다.
네트워크의 모든 노드가 동일하게 작동하는 통신 모델.
- Not Centralized, 클라이언트가 서버이자 라우터이기도 하다.
- Self Organization (Join and Leave이 매우 잦다.)
- Node들은 Unreliable하고, Heterogeneous (신뢰할 수 없음, 이기종)
- Fault Tolerant (결함 내성)
- Peer Node에서 분산된 공유 리소스를 활용한다. Peer가 많이 들어오면 그만큼 트래픽이 증가한다.
- Resource는 Node들이 제공하며, Peer들에게 배포된다. Peer는 정보를 찾기 위해 여러 Peer와 통신해야 할 수도 있다.
장점
- 자원사용 효율성 : 사용되지 않는 Stroage, Bandwith 이용가능
- Scalability : 리소스를 공유할 수 있고, 모은 자원들이 자연스럽게 증가
- Reliability : 일부 Node가 작동하지 않아도 괜찮음. SPoF
- 관리 용이 : 관리도 노드별로 분산되어있어 편하고, 요구를 만족시키기 위해서 서버를 배치하지 않아도 된다.
단점
- 모든 노드가 동일하지 않음 → 전체 퍼포먼스에 영향을 줄 수 잇음(어떤건 빠르고, 어떤건 느림)
- Global State의 일관적인 유지가 복잡함 → Decentralized에서 나오는 단점
P2P 파일 공유 애플리케이션
파일 공유, 프로세스 공유, 협업 환경 조성 → Napster, Gnutella, Freenet, KaZaA등
대규모 연산, 데이터 분석, 데이터 마이닝 → SETI 등
Napster
특징
Central indexing and searching service : 중앙 색인 및 검색 서비스
Hybrid P2P : 완전한 Not Centralized가 아님, 중앙 집중식 데이터베이스 사용
서버에 리소스를 가지고 있는 Peer의 위치를 저장해두고, 리소스 요청 시 서버는 파일을 주는 것이 아닌 소유한 Peer의 정보를 넘겨주는 것
과정
- Join : Central Server에 접속
- Publish : 파일을 Central Server에 등록함
- Search : 서버에 질의 → 저장된 누군가의 파일을 돌려줌 (O(1))
- Fetch: 직접적으로 Peer로부터 다운로드받게 됨
장점
- 올바른 결과 보장
- 파일 전송은 직접적이다.(P2P)
단점
- SPoF, Scalability Bottleneck → Centralized Server의 단점
- 서비스 거부에 취약
Napster 개선
연결 속도, 오랫동안 살아있는 Peer, 가까운 Node 등을 우선순위로 하여 서버는 클라이언트를 조사하고 데이터 소스의 순위를 매기면서 상태를 추적함.
Gnutella
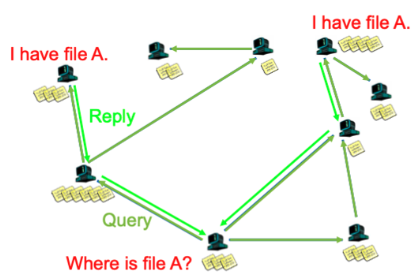
Napster(Hybrid Centralized) <-> Gnutella : 네트워크가 분산되어 있어 중앙 서버 X.
Query Flooding (쿼리 홍수) 방식 사용
- 사용자는 특정 파일을 검색하고자 할 때 해당 쿼리를 네트워크에 뿌린다.
- 쿼리는 사용자의 노드에서 시작하여 네트워크 상의 다양한 노드로 전파된다.
- 네트워크 상의 다양한 노드에 도달한 쿼리는 해당 노드들이 가지고 있는 정보를 기반으로 응답을 생성한다.
- Join (참여): 클라이언트가 시작될 때, 해당 클라이언트는 몇몇 다른 노드에 연락. 이러한 노드들은 클라이언트의 neighbors이 됨
- Publish (게시): 게시(공유) 과정이 필요하지 않음
- Search (검색): 파일을 검색하려는 사용자는 자신의 이웃 노드들에게 쿼리를 보내고 이웃 노드들은 이를 다른 이웃들에게 전파시킨다. 노드들은 이에 따른 응답을 생성하여 보낸다.
- Fetch (가져오기): Search로 얻은 파일의 정보 해당 파일을 가진 피어에게 파일을 요청하고 가져온다.(P2P)
장점
- Decentralized
- 검색 비용이 분산됨
단점
- Node가 자주 떠나고, 네트워크 형성이 불완전하다.
- 중복된 Message가 매우 많아 Bandwidth 낭비가 심하다.
- 검색 시간에 대한 시간 복잡도를 예상할 수 없다.
KaZaA
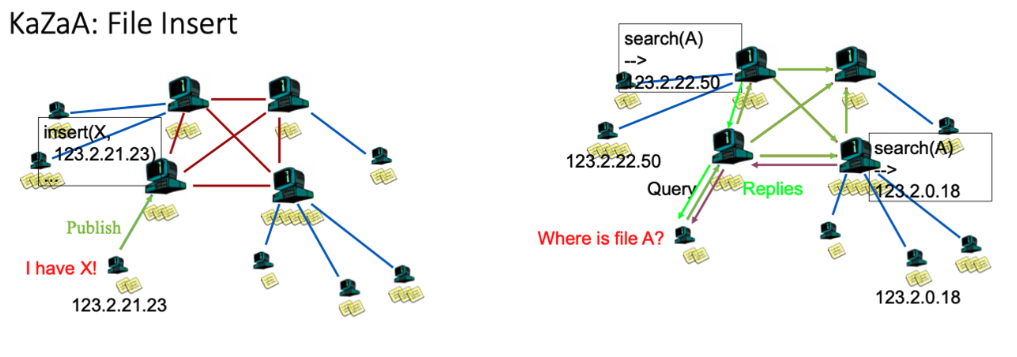
Gnutella(불완전한 네트워크 구조) → KaZaA : 구조화된 P2P 네트워크를 사용
Smart(Intelligent) Query Flooding (지능적인 쿼리 홍수): 사용자가 파일을 검색할 때, 해당 쿼리를 더 효율적으로 처리하기 위해 지능적인 알고리즘이 사용
- Join (참여): 클라이언트가 시작될 때 Supernode에게 자신의 파일 목록을 보내고, Supernode와의 연결을 통해 네트워크에 참여한다. 어느 시점에 자신이 Supernode가 될 수 있음.
- Publish (게시): 자신의 파일 목록을 Supernode로 보낸다.
- Search (검색): 파일을 검색하려는 사용자는 supernode에게 쿼리를 보내고, 쿼리를 받은 supernode는 다른 supernode들에게 Query를 Flooding한다.
- Fetch (가져오기): Peer로부터 직접 파일을 가져온다.
장점
- 노드 이질성 고려 (Node Heterogeneity): 대역폭, 컴퓨팅 리소스, 가용성 등을 고려한다.
- 네트워크 지역성 고려
단점
- 검색 범위, 시간에 대한 보장 X
BitTorrent
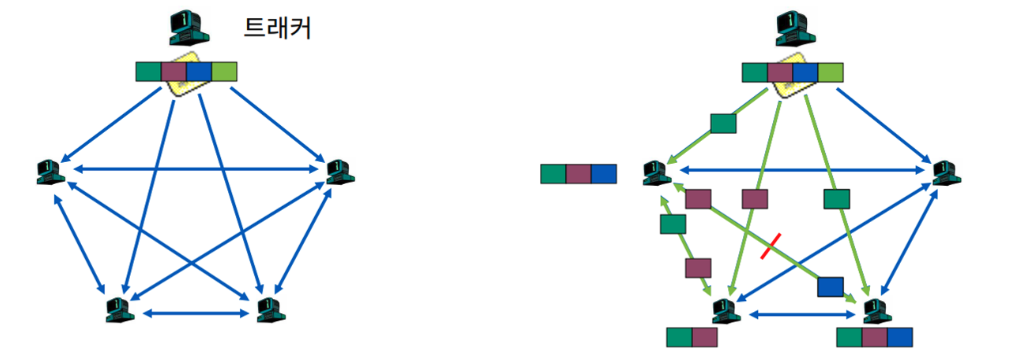
내가 파일을 공유받는 것과 동시에 공유받는 형식. Searching보다 효율적인 Fetching에 집중함.
"Pull-based" 및 "Swarming" 접근 방식을 채택하며, Searching과 같은 기능을 수행하지 않음.
Swarming 접근 방식: Pull-based 접근 방식 → 파일을 원하는 사용자가 필요한 만큼 가져옴.
- 각 파일은 작은 조각으로 나뉨 → 여러 노드가 서로 다른 조각을 동시에 다운로드하고 공유(서로서로 부족한 조각을 공유)
- 파일은 순차적으로 다운로드되지 않고, 각 노드는 필요한 조각을 가진 이웃 노드로부터 받아옴
- 모든 참여 노드의 기여
용어
- Seed (Seeder): 전체 파일을 가진 Peer
- Original Seed (최초 Seeder): 최초 업로드 Seeder
- Leech (Leecher): 파일을 다운로드 중인 Peer, 조각을 다운로드하면 해당 조각의 복제본이 생성
- Sub-piece (서브피스): 다운로드 시 서브피스 단위로 조각을 요청하고 공유, 노드는 다운로드한 파일 조각을 모두 조립한 후에 다른 노드에게 업로드를 시작
Swarming
- Join (참여): 중앙 집중식 Tracker 서버에 연락하여 해당 파일에 대한 Peer 목록을 얻어냄
- Publish (게시): 트래커 서버를 실행(운영)하여 파일을 공유
- Search (검색): 검색은 BitTorrent 자체에서 직접 수행하지 않음. 대신 외부 수단(Google 등)을 통해 해당 파일에 대한 트래커를 찾는다.
- Fetch (가져오기): 트래커를 통해 얻은 피어들로부터 파일의 작은 조각들을 다운로드 → 파일의 여러 부분을 동시에 다운로드 → 얻은 파일 조각을 다른 피어들에게 업로드
장점
- Hot Content에 대해 성능이 뛰어나다.
- Piece 단위로 여러 Peer들에서 Resource를 가져오므로 분산 컴퓨팅 측면에서 좋다.
- Peer들에게 리소스를 공유하도록 인센티브를 제공 → Free loader를 피한다.
단점
- Swarm Bootstrap을 위한 Central Tracker Server가 필요함 → SPoF
Structured P2P
네트워크 토폴리지를 정의하고, 리소스 배치 규칙을 정의한다. ⇒ 효율적인 Object Search 보장, 리소스 위치 및 로드 밸런싱을 단순화할 수 있다. DHT 등의 자료구조와 규칙을 따름
DHT(Distributed Hash Tables)
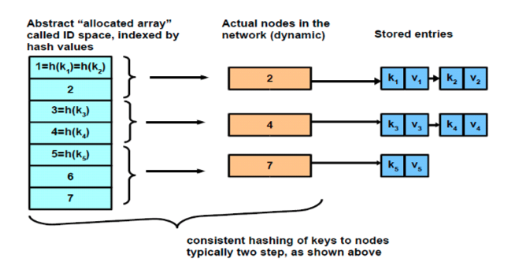
네트워크에서 효과적인 데이터 분산과 검색을 제공하는 분산 데이터 저장 시스템
파일 시스템과 같이 검색 및 성능이 보장되어야 하는 응용 프로그램에 적합하다.
DHT는 BitTorrent, Chord, Kademlia 등과 같은 프로토콜과 알고리즘을 사용하여 구현
목적
- 시스템 파일에 대한 조회의 성공을 보장
- 검색 시간의 증명 가능한 범위 입증
- Scalability
아이디어 : 특정 컨텐츠(혹은 포인터)를 보유하도록 특정 노드를 할당. 노드가 해당 컨텐츠를 원할 때 이를 보유한 노드로 이동
과제
- Distributed : 기존 노드 간의 Resposibilities를 분산
- Adaptive(적응형) : P2P Overlay에 Join/Leave → 참여하는 노드에 책임을 분배하고, 노드가 떠나며서 책임을 재분배
1. Hash Table functionality in a P2P network:
- DHT는 분산 시스템에서 해시 테이블과 같은 기능을 제공
- 데이터는 키로 색인, 해당 키를 기반으로 데이터를 검색, 각 키는 해시 함수를 사용하여 특정 노드에 매핑.
- 각 키에는 해당하는 고유한 라이브 노드가 할당. 이는 데이터를 저장하고 검색하는 데 사용
2 Maintenance, optimization, load balancing:
- DHT는 오버레이 네트워크에서 효율적으로 노드를 유지, 최적화하고, 부하 분산을 달성하기 위한 작업 수행
3. Replicate: 내구성을 높이기 위해 특정 데이터 항목을 여러 노드에 복제
4. Decentralized: 분산 구조를 가지며, 각 노드는 제한된 수의 이웃 노드와 직접 통신
5. Performance: Search 및 노드 Join/Leave 작업에 대한 성능을 보장. → 검색 시 필요한 메시지는 한정되어 있음(추정 가능). 최소 노드에만 영향이 감
장점 : 보장된 Lookup(조회), O(logN)의 상태 및 검색 속도
단점 : 정확하지 않은 검색 지원이 어려움. 실제 사용은 매우 어려움
Chored
1. 순서가 지정된 Ring Overlay 기반
2. 일관된 해싱 : 모든 Node들은 거의 동일한 Load를 가짐.
3. 로컬 연산 : 노드를 추가하거나 제거하는 작업은 O(1/N) 비율로 이루어져, 키의 일부만 새 위치로 이동
조회(Lookup)
해당 키를 저장하는 노드를 찾는 과정
Primitive Key Lookup
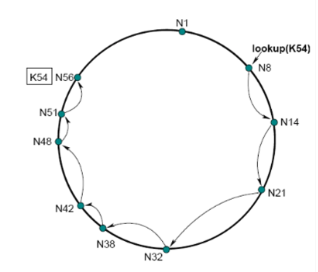
조회 쿼리가 일방으로 계속 원을 중심으로 전달. 최악의 경우 O(N)
Scalable key Lookup
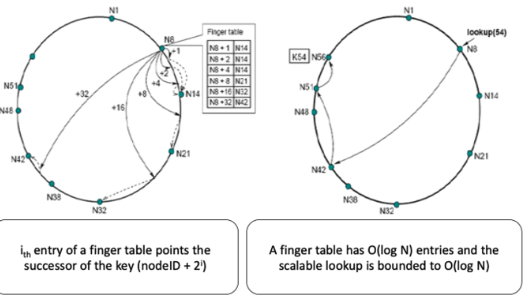
- Routing Table: 각 노드 n은 최대 m개의 항목을 가진 라우팅 테이블을 유지(finger table)
- 테이블의 i번째 항목은 Successor(후속자)의 위치를 가리킴. 식으로 나타내면 (n + 2^(i-1))
- 주어진 식별자(키)에 대한 쿼리는 각 노드에서 m개의 항목 중 가장 가까운 노드로 전달
- 검색 비용: O(log N). (여기서 m = O(log N)
Node Join / Leave
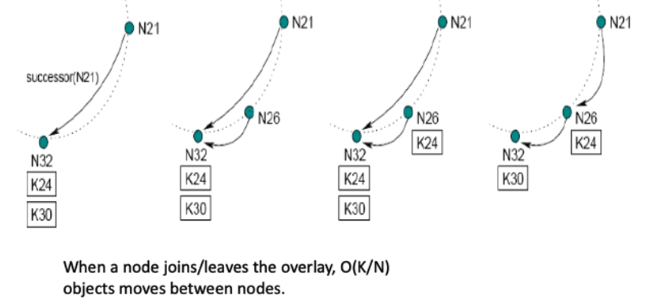
Join
- 새로운 노드(N)는 Successor를 탐색함(조회 수행) → Finger Table 구축 / 다른 노드의 Finger Table 업데이트
- 새로운 노드가 Successor의 Key를 인수함
- Predecessor(전임자)을 Successor(후임자)의 Pre-Predecessor로 설정
Leave
- 노드가 담당하는 모든 Key를 Successor로 이동
- Successor의 Predecessor를 나의 Predecessor로 설정
- Predecessor의 Successor를 나의 Successor로 설정
Stabilization(안정화)
- 링이 정확하면 라우팅이 올바른 것이다.
- 각 노드는 주기적으로 안정화 루틴을 실행한다. (정기적인 Finger Refresh, O(logN))
실패 처리
- Replication : Successor(후임자)를 여러개를 둠 → 노드 오류에 강력
- Routing 대체 경로 : Finger가 반응하지 않으면 이전 Finger 혹은 Replicas를 가져온다.
결론
- SPoF(Centralized)는 숙적
- Message가 중복되는 것은 Bad.
- 기초적인 네트워크 토폴로지가 중요하다.
- 모든 노드들은 상이(Heterogene)하다.
- Freeloading(무료 다운로드)를 억제하려면 인센티브가 필요하다(Swarming, Bittorrent)
- Structured P2P는 최소 보장을 제공하는 동시에 한계가 명확하다
Content / Image Reference
Tannenbaum and Van Steen :: Distributed Systems: Principles and Paradigms (PDF)
'CS > 아키텍쳐 & 분산시스템' 카테고리의 다른 글
| [CS] 클라우드 컴퓨팅 모델 (0) | 2024.01.10 |
|---|---|
| [CS] Web Proxy와 CDN(Content Delivery Network) (1) | 2024.01.07 |
| [CS] 아키텍쳐 관점에서의 DNS와 Namespace (0) | 2024.01.07 |
| [CS] 분산 시스템의 핵심목표 : Fault Tolerance(결함 내성) (1) | 2024.01.05 |
| [CS] 분산환경의 복제(Replication)와 일관성(Consistency) 유지 (0) | 2024.01.05 |








