
[CS] 분산 시스템의 핵심목표 : Fault Tolerance(결함 내성)

Fault Tolerance
분산 시스템에서 하나 이상의 장치의 실패에도 계속해서 정상적으로 동작할 수 있는 능력을 의미한다.
시스템의 안정성과 가용성을 보장하며, 장애가 발생했을 때에도 서비스의 중단을 최소화하는 목표를 가진다.
용어
- Failure : 정상적인 기능을 수행할 수 없는 상태(메시지 손상)
- Error : 의도와 정확성에서 의도치 않게 벗어나는 행위(0대신 1을 읽는 것)
- Fault : Error의 원인 (설계, 제조결함, 성능저하 등..)
- Recursive : Failure은 Fault가 될 수 있음.
- 제조 결함(Fault) → 디스크 오류(Failure)
- 디스크 장애(Failure) → 데이터베이스 장애(Failure)
- 데이터베이스 장애(Failure) → 이메일 서비스 장애(Fauilure)
Failure
- Partial Failure : 분산 시스템이 Single Machine과 구분되는 차이점. 일부 노드가 실패하고 다른 노드는 계속 작동할 수 있음.
- 분산 시스템 : Fault Tolerant(내결함성), 신뢰할 수 있는 시스템이어야 함.
- Dependability(신뢰성) → 다음 사항을 포함
- Availabilty(유효성) : 시스템이 제대로 작동, 즉시 사용 가능해야 함.
- Reliability(신뢰할 수 있음) : Failure 없이 계속 작동되어야 함
- Safety(안전) : 시스템 오류 시에도 심각한 일은 발생하지 않아야 함
- Maintainability(유지 관리성) : 시스템 복구가 간단한가?
- Dependability한 시스템을 구축하는 방법
- Fault Prevention : 결함 발생 방지
- Fault Removal : 결함의 존재, 수, 심각성을 줄인다.
- Fault Forecasting : 결함의 수치를 추정하고 예측
- Fault Tolerance : 결함이 있는 경우에도 사양을 충족할 수 있도록 컴포넌트를 구성
- Faults의 유형
- Transient Faults(일시적 결함) : 한번 발생하고 사라짐(무선통신 중 방해..)
- Intermittent Faults(간헐적 결함): 예측할 수 없고 악명이 높음. (커넥터의 접촉이 느슨한 경우)
- Permanent Faults(영구적 결함): 구성요소의 수리 이전까지 지속(소프트웨어 버그..)
- Failure Model
- Crash Failure(충돌) : 서버저 중지되지만 올바르게 작동. 가장 심각하지 않음
- Omission Failure(누락) : 메시지 요청을 받지 못하거나 응답을 하지 못함
- Timing Failure(타이밍) : 응답이 지정된 Interval을 벗어남
- Response Failure(응답) : 응답이 올바른 값이 아님, 제어 흐름에서 벗어남
- Arbitrary Failure(임의의 실패) (=Byzantine Fauilure) : 정상 동작과 상관없는 임의의 시간에 임의의 응답을 생성함. 최악의 케이스
Failure Detection
Crashed Component와 네트워크, 컴퓨팅 자원 등의 Latency로 발생하는 Slow Component를 어떻게 구분할 것인가에 대한 이슈.
이를 구분하여 Failure를 감지할 수 있어야 한다.
- Fail-stop: 컴포넌트가 충돌한 경우, 이러한 충돌이 감지될 수 있다는 가정
- Fail-silent: 컴포넌트가 충돌하거나 일부 작업을 생략하는 경우, 클라이언트가 정확히 어떤 일이 발생했는지 알기 어려운 상황
- Fail-safe: 컴포넌트가 임의의 실패를 경험하더라도 그 실패가 악영향을 미치지 않는 경우를 의미
일반적으로 Timeout 메커니즘이 사용됨. → 적절한 Time을 설정하기는 어렵고, 조기 시간 초과로 인한 오탐지 및, 프로세스 Failure / 네트워크 Failure를 구별할 수 없음.
- Actively : 살아있냐고 묻는 Message를 적극적으로 보내고 Answer를 기다리는 방법
- Passively : 다른 프로세스에게서 Message가 올 때 까지 기다림
Failure Tolerance(결함 허용)
- 결함 발생이 전체 성능에 심각한 영향을 주지 않고 부분적인 오류를 복구할 수 있어야 함.
- 테크닉
- Prevention(예방)
- Prediction(예측)
- Masking(결함 발생을 숨김)
- Recovery(회복, 복원)
Recovery Strategires
Backward Recovery : 체크포인트를 저장하여 이전 Error-Free 상태로 만든다.
- 단점 : 체크포인트의 비용이 많이 든다. (스냅샷 비용 + 모든 프로세스의 재시작)
- 체크포인트 : 프로세스들이 State를 수시로 Local Storage에 저장해둠. → 오류 발생 시 가장 최근의 상태를 가져옴
- Independent Checkpoint : 각 프로세스가 독립적으로 스냅샷을 찍음. Inconsistent한 Cut을 형성하는 경우 정상을 찾을 때 까지 계속 롤백해야 함(도미노 효과)
- Coordinated Checkpoint : 프로세스들 간 전역적으로 협의 후 스냅샷을 찍음.
- 코디네이터가 체크포인트 요청을 멀티캐스트 한 이후, Participant들이 체크포인트 획득 및 보고를 코디네이터에게 알린다.
- Messaging Logging : 체크포인트는 비용이 많이 든다 → Message Logging의 저렴한 Cost 결합이 해결책이 될 수 있음
-> 체크포인트 사이의 Message를 기록, 복구하려면 이전 체크포인트 이후의 메시지들을 복구하면 된다.
Forward Recovery : 시스템이 계속 작동할 수 있는 새로운 상태로 만듬. → 오류 수정 코드
- 단점 : 모든 잠재적인 오류를 미리 고려해야 함.
프로세스 그룹
프로세스 모음의 추상화. Faulty Process를 허용하기 위해서 중복된 작업을 수행하는 프로세스들이라고 생각하면 된다.
그룹의 모든 Member들은 Message를 받음. 하나가 실패 시 다른 프로세스가 대체하게 된다.
그룹은 동적일 수 있으며, 프로세스 그룹과 멤버십을 관리하는 메커니즘이 필요하다.
Flat Groups(평면적 그룹) : 모든 그룹 구성원과 즉시 정보 교환이 이루어짐.
- 장점 : Fault Tolerance, SPoF 없음
- 단점 : 구현이 어려움, Completely Distributed → Overhead 발생
Hierarchical Groups(계층적 그룹) : 단일 Coordinator를 통한 통신
- 장점 : 구현하기 쉬움
- 단점 : 실제로는 Fault Tolerant / Scalable하지 않을 수 있음
Group Membership : 그룹을 추가/삭제하고, 그룹 가입/탈퇴를 관리하는 방법
- Centralized : 각 그룹에 대한 데이터베이스를 유지관리하는 중앙 그룹 서버를 보유
- 장점 : 효율적이고 구현하기 쉬움
- 단점 : SpOF
- Distributed : 그룹에 참여하거나 떠나려면, 모든 그룹 구성원들에게 메시지를 보낼 수 있음. 충돌이 발생하면 이를 발견하고 그룹에서 제거해야 한다.
Redundency와 Failure Masking
Redundancy(중복성) : Failures를 숨기는 핵심 기술, 하나의 구성 요소의 실패에도 중복 요소에 의해 시스템이 계속해서 동작할 수 있도록 하는 방법이다.
- Information : 추가적인 정보를 붙이는 방법
- Time : 성공할 때 까지 작업 수행
- Physical : 추가 Components(SW / HW) → 프로세스 복제 등..
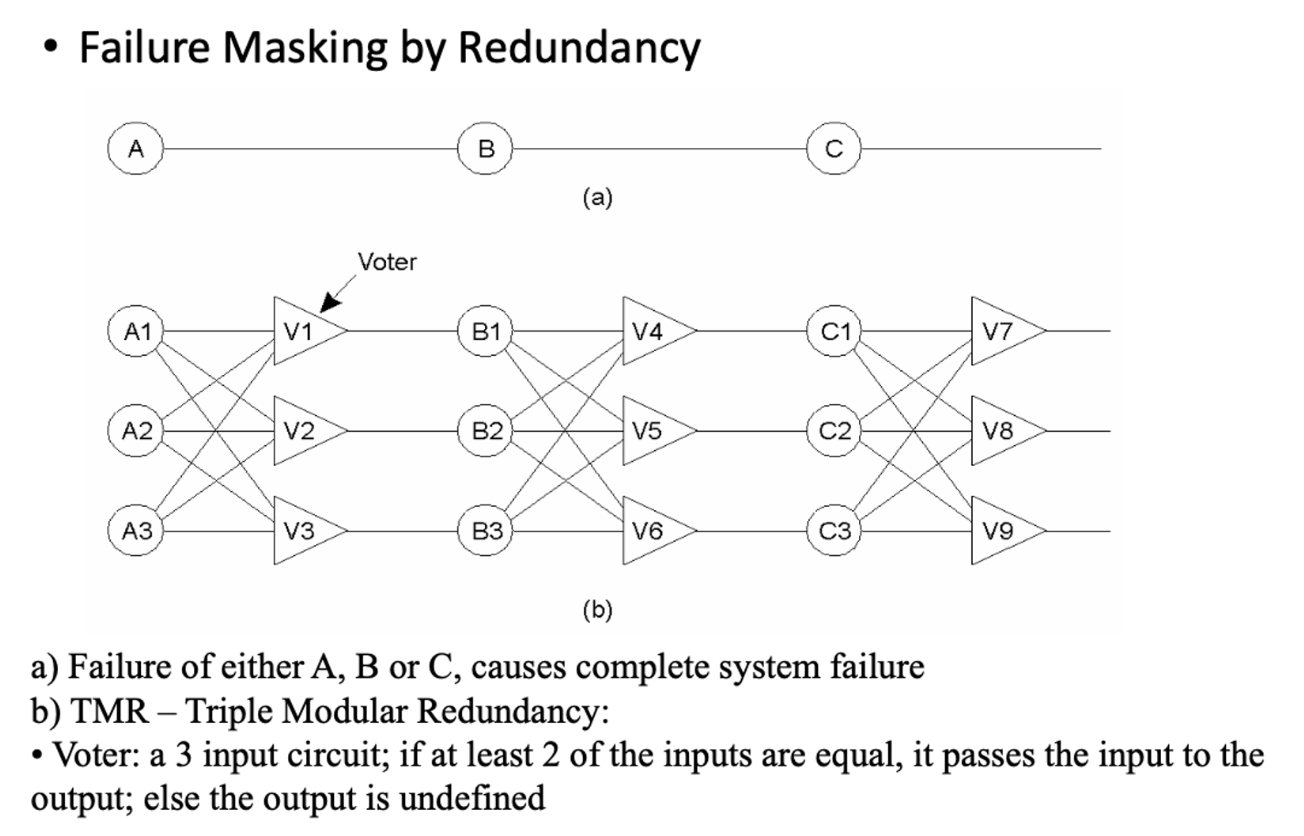
a)의 경우 A, B, C 중 하나만 Failure가 발생해도 전체 시스템에 영향이 간다.
b)의 경우 여러개의 프로세스(머신)에서 Redundency한 작업을 수행하게 한다. 따라서, A1, A2, A3 중 하나가 Failure가 발생해도 나머지 두개가 살아있다면, 과반수 이상의 Vote가 이루어져 시스템을 계속 수행할 수 있다.
Byzantine Agreement Problem
- 프로세스 Group Output은 Voting으로 결정되고, 이를 위해 2K + 1개의 Compoment가 필요하다. (과반수 이상, K가 틀리면 K+1이 맞아야 함)
- Byzantine Agreement Problem : Faulty Components들이 협력하여 속임수를 쓸 수 있음
- 속임수에는 악의적인 노드가 일부 구성 요소를 공격하여 정상적인 통신을 방해하거나 무효화시키거나, 거짓 정보를 전송, 여러 개의 가짜 노드를 생성하는 등이 있을 수 있다.
- 프로세스 그룹은 계산 결과, Leader 선출, Synchronization, Transaction Commit 등의 합의를 위해 필요했다.
- Agreement는 매우 어려움 : Communication, Process(Fail 혹은 Team을 이루어 잘못된 결과) 등 잘못될 수 있음.
- 목표 : 결함이 없는 프로세스들의 Agreement의 합의 도달. 다음을 가정하고 합의를 이룸.
-> 프로세스는 비동기적 동작, 메시지 전송은 Unicast, Communication Delay 제한이 없음)
Lamport's Agreement & Byzantine Fault Tolerance
아래 내용은 Lamport Agreement를 적용하여 합의 알고리즘을 진행하는 케이스들이다.

결론은 Byzantine Fault Tolerance 원칙에 의해 F개의 Faulty Process를 허용하려면 3F + 1의 전체 Process가 필요하다.
왜 3F+1 인지는 아래의 블로그 글을 참고하면 좋을 것 같다.
https://blog.seulgi.kim/2018/04/byzantine-fault-tolerance-n-3f-1.html
Byzantine Fault Tolerance 시스템에서 N = 3f + 1인 이유
Byzantine Fault Tolerance에서 전체 크기가 failure 노드의 3배보다 많아야 하는 이유.
blog.seulgi.kim
Content / Image Reference
Tannenbaum and Van Steen :: Distributed Systems: Principles and Paradigms (PDF)
'CS > 아키텍쳐 & 분산시스템' 카테고리의 다른 글
| [CS] Web Proxy와 CDN(Content Delivery Network) (1) | 2024.01.07 |
|---|---|
| [CS] 아키텍쳐 관점에서의 DNS와 Namespace (0) | 2024.01.07 |
| [CS] 분산환경의 복제(Replication)와 일관성(Consistency) 유지 (0) | 2024.01.05 |
| [CS] 분산 시스템에서의 리더 선출 알고리즘 (1) | 2024.01.05 |
| [CS] 분산 상호 배제 (Distributed Mutual Exclusion) (1) | 2024.01.05 |








