

[CS] 프로세스와 스레드 및 병렬 처리 기법
1. 프로세스의 개념
프로그램 : 저장장치에 저장되어 있는 정적인 상태
프로세스 : 실행을 위해 메모리에 올라온 동적인 상태
2. 프로세스 상태

프로세스 상태
- new(생성) : 프로세스가 메모리에 올라와 실행 준비 완료. 메모리 할당, PCB 생성
- ready(준비) : 생성된 프로세스가 CPU를 얻을 때 까지 기다리는 상태. PCB는 Ready Queue에서 대기. CPU 스케줄러에 의해서 관리
- runnng(실행) : 준비 상태에 있는 프로세스가 CPU를 얻어 실제 작업을 수행. 타임 슬라이스 동안 작업
- terminated(완료) : 실행 상태의 프로세스가 주어진 타임 슬라이스 내에 작업을 마침. 프로세스 종료, PCB 폐기
- waiting(대기) : 실행 상태의 프로세스가 입출력을 요청하면 입출력이 완료될 때 까지 대기하는 상태
3. PCB

각 프로세스와 관련된 정보가 포함되어 있음.
PC, CPU Register, 메모리 관리 정보, Accounting(Time used, ID) 정보, I/O 상태, 스케줄링 데이터(우선순위 등), 프로세스 상태 등..
- 포인터 (Pointer): Ready, Waiting 상태의 큐를 구현할 때 사용
- 프로세스 상태 (Process State): 현재 프로세스가 어떤 상태에 있는지를 나타낸다. 주요 상태로는 생성(New), 준비(Ready), 실행(Running), 대기(Waiting), 종료(Terminated)
- 프로그램 카운터 (Program Counter): 프로세스가 다음에 실행할 명령어의 주소를 가리키는 레지스터. 프로세스가 다시 실행되면 이 주소에서부터 명령어를 수행하게 된다.
- 레지스터 정보 (Register): 프로세스가 실행되던 중 사용하던 레지스터 내용을 저장. 프로세스가 다시 실행될 때 이전 상태로 복원하는 데 사용
- 프로세스 식별자 (Process ID): 각 프로세스를 고유하게 식별하는 식별자
- 프로세스 우선순위 (Priority): 프로세스에 할당된 우선순위를 나타낸다. 스케줄링 알고리즘에서 사용되어 어떤 프로세스가 다음에 실행될지 결정
- 프로세스 계정 정보 (Accounting Information): CPU 사용 시간, 실제 사용된 시간 등과 같은 계정 정보를 저장
- 메모리 관리 정보 (Memory Management Information): 프로세스가 사용 중인 메모리 주소 영역의 정보. 경계 레지스터와 한계 레지스터 값 등이 있음
- 입출력 상태 정보 (I/O Status Information): 프로세스가 현재까지의 입출력 상태 및 대기 중인 입출력 작업에 대한 정보를 유지
- 열린 파일 목록 (List of Open Files): 현재 프로세스가 열어둔 파일에 대한 정보를 포함
- 할당된 자원 정보
- 부모 프로세스 / 자식 프로세스 구분자 : 부모 : PPID, 자식 : CPID
- 스케줄링 및 스위칭 정보 (Scheduling and Switching Information): 프로세스의 스케줄링 및 스위칭에 필요한 추가적인 정보가 여기에 포함. 스케줄링 큐에 대한 포인터 등
4. Context Switch (문맥 전환)
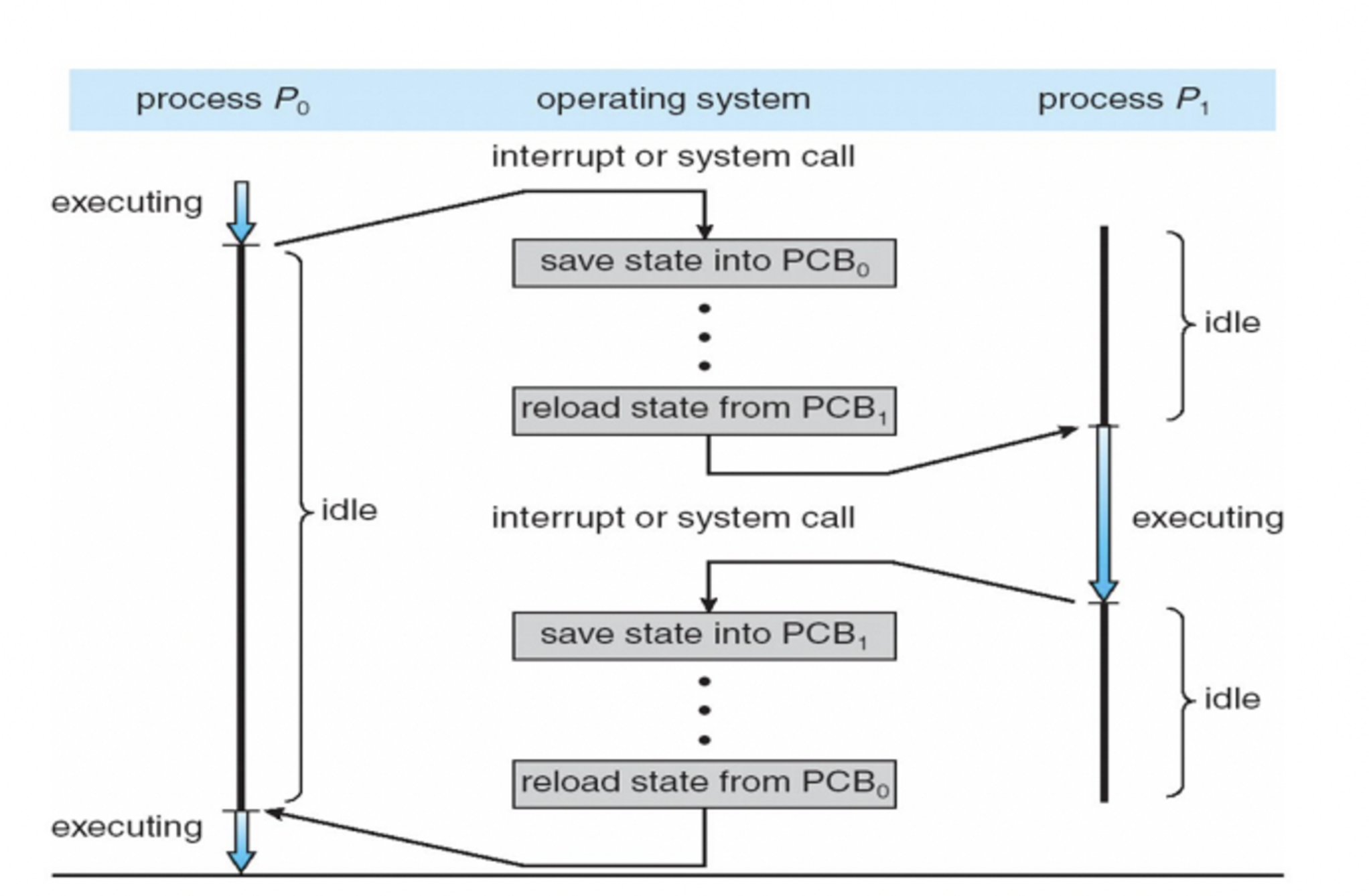
CPU를 사용하고 있는 프로세스를 전환하는 과정
- 이전 프로세스 상태를 Register에 저장 → 새로운 프로세스의 PCB 내용으로 CPU가 다시 세팅
- 컨텍스트 전환 시간 → 오버헤드 → OS와 PCB가 복잡할수록 컨텍스트 스위칭 시간이 길어짐
- 하드웨어에 따라 오버헤드가 달라짐 → 일부 하드웨어는 CPU가 여러 레지스터 Set을 지원
Processe vs. Thread
Thread
- 스케줄러가 CPU에 전달하는 작업 단위
- 운영체제의 작업단위 : 프로세스 → 프로세스로부터 전달받은 스레드 → 스레드는 경량 프로세스의 개념
- 전통적 프로세스 : 단일 제어 스레드
- 전통적 UNIX 프로세스는 fork를 사용하여 상위 프로세스 → 하위 프로세스 생성
- fork는 비용이 많이 든다.
- 전통적 프로세스 : 단일 제어 스레드
- 스레드는 전체 Address Space(Memory)를 공유하며 접근 가능 → 공유가 쉬움.
- 잠재적인 병렬 처리가 가능함
- 프로세스 Context Switch에 비해 낮은 오버헤드를 가짐
- 각 스레드에는 자체 스택, PC, Register가 있음
- 프로세스와 달리 동일한 메모리와 파일(코드영역/데이터영역) 공유 → 데이터 전달속도 빠름
- Shared Data에 대한 동기화(Synchronization)가 필요할 수 있음
Multi-Thread의 예시
- Client : 웹 브라우저
- Server : Apache
쓰레드 구현
Thread 패키지 형태로 제공 → 생성, 제거 등을 하는 라이브러리가 제공, OS 커널레벨 / 유저레벨 로 제공될수있음.
User-level vs. Kernel-level threads
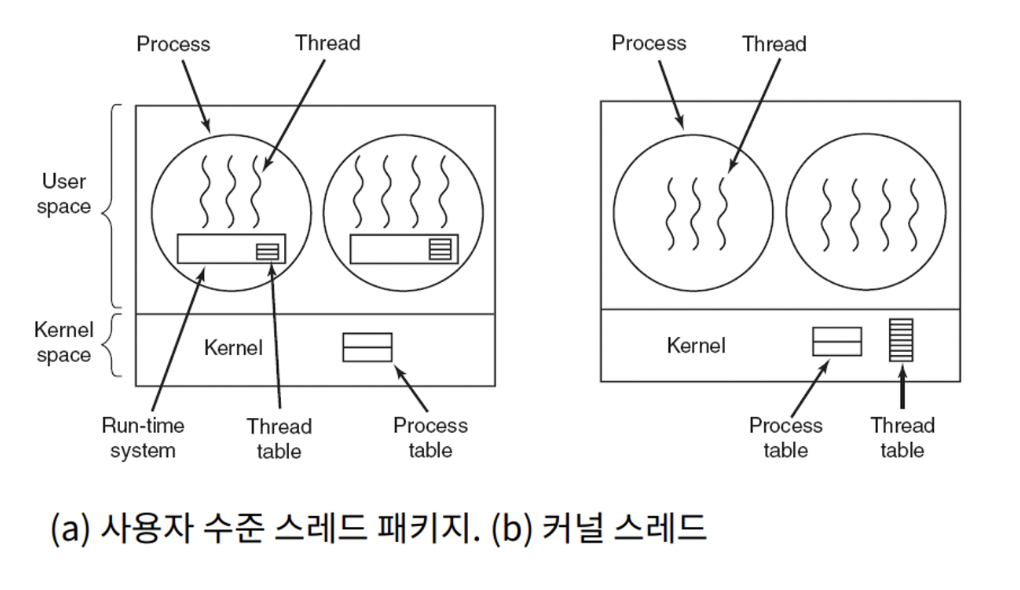
User-level 스레드
- 장점
- Transperency : 애플리케이션으로 관리되며, 커널 입장에서는 스레드가 있는지 모름.
- 저비용 : 스레드를 지원하기 위해 커널을 수정하지 않아도 됨 → 저렴하고 빠른 Context Switching
- 효율성 : 운영체제(커널)의 도움을 받지 않아도 됨 → 시스템콜X
- 맞춤형 스케줄링 : 애플리케이션마다 특정한 스케줄링 종속가능
- 단점
- 시스템 콜의 블로킹 회피 필요
- 스레드 간 경쟁
- 멀티 프로세서의 장점을 이용할 수 없음
Kernel-level 스레드
- 장점 : 커널이 스레드의 존재를 인식. 커널에 맞추어, 스레드들 병렬처리.
- 더 나은(But expensive) 스케줄링 결정 가능
- 멀티프로세서, 멀티코어에 적합
- 각 스레드에서 Blocking(차단) I/O 호출 가능, 여러 프로세서에서 동시에 실행 가능
- 단점 : 커널에 스레드들을 지원하기위한 자료구조, 스케줄링 등이 지원되어야 함 → 오버헤드 발생, 자원이 많이듬(expensive)
- Windows, Linux, Mac OS 등
Trade-Off(절충안) : Multiple User-level Thread를 Kernel-level Thread로 연결
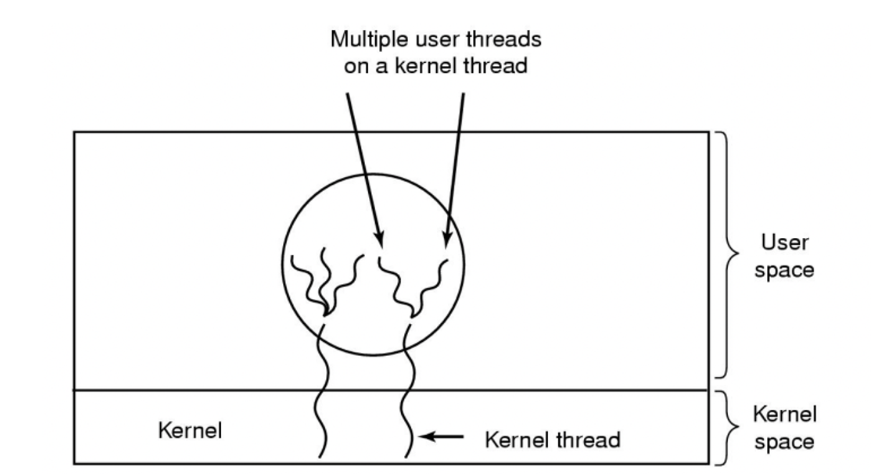
- Kernel-level thread
- 각 스레드는 Blocking I/O 호출 가능
- Multi processors에서 동시에 실행 가능
- User-lever thread
- 빠른 컨텍스트 스위칭
- 맞춤형 스케줄링
- 커널의 지원을 받지 않음(System Call X)
Concurrent Programming
Concurrency를 추가해야 하는 경우
- 여러 작업을 동시에 수행할 수 있는 작업 또는 여러 작업에서 작업할 수 있는 데이터에 대해서
- 잠재적으로 긴 I/O 대기를 차단 → 어떤 곳에서는 CPU 사이클을 많이 사용하지만 다른 곳에서는 사용하지 않음
- 비동기 이벤트에 응답해야 함
Concurrent Programming
- 둘 이상의 스레드 혹은 프로세스, 각각은 병렬로 실행되고 실행 속도를 에측할 수 없음, 스레드는 공유 변수에 대해 엑세스하여 상호 작용이 가능함
- Multi-Thread Server
- READ와 WRITE의 순서가 달라지는 문제가 발생할 수 있음! → 동기화 문제 해결해야 함
Multi-Thread Server
Multi-Thread 서버의 구성 방법
- Manager / Worker Model
- Manager(Single Thread)가 다른 스레드들(Workers)에 작업을 할당
- Worker Thread가 너무 없거나 너무 많은 문제 해결 필요
- Pipeline
- 작업(Task)를 하위 작업(Sub-task)으로 나눔
- 각각의 Sub-task는 다른 스레드에 의해서 처리됨
- 하위 단계 별 스레드 균형 조절 필요
- Peer
- Manager / Worker Model과 유사함
- 메인 스레드가 다른 스레드를 생성한 후, Work에 참여함
Multi-Thread 서버
- 싱글 쓰레드 서버에서는 System call 시 프로세스 전체가 블로킹됨
- Multi processor(다중 프로세서) 시스템에서 프로그램을 실행할 때 병렬성 활용(각 스레드를 다른 CPU에 할당) → Concurrency
- 성능 향상
- 새 프로세스를 시작하는 것(Multi Processing) 보다 저렴
- Network latency(지연 시간)을 Hide → Transparency
- 이전 요청에 응답하는 동안에 다음 요청을 처리할 수 있음
- 구조 향상
- 간단하고 이해하기 쉬운 I/O는 전체 구조를 단순화시킴
- 제어 흐름이 단순화되어 크기가 작고 이해하기 쉬움
Multi-Thread 서버 아키텍처
- Worker Pool: 사전에 정의된 크기의 고정된 스레드 풀을 사용하는 아키텍처. 이 풀은 일반적으로 작업을 처리하는 데 사용
- 특징:
- 스레드 크기는 변경되지 않으며 사전에 정의됨.
- 작업에 우선순위를 부여할 수 있지만 유연성이 제한됨.
- 특징:
- Other Architectures:
- Thread-per-request:
- 각 요청(Request)마다 새로운 스레드를 생성하는 아키텍처
- Thread-per-connection:
- 각 연결(Connection)마다 새로운 스레드를 생성하는 아키텍처
- Thread-per-object:
- 각 객체(Object) 또는 작업(Work)마다 새로운 스레드를 생성하는 아키텍처
- Thread-per-request:
- Physical Parallelism:
- Multiprocessor/Multicore Machines:
- 물리적으로 병렬 실행 가능한 여러 프로세서 또는 코어가 있는 시스템. 이러한 시스템에서는 여러 작업이 동시에 실행될 수 있음
- 여러 프로세서 또는 코어가 병렬로 동작함.
- Multiprocessor/Multicore Machines:
스레드의 병렬 처리 기법
파이프라인 기법
병렬 처리의 기법 중 하나로 이 기법은, 데이터 처리과정을 단계별로 나누어하는 분업의 개념과 유사하다.
CPU의 프로그램 처리 속도를 높이기 위하여 CPU 내부 하드웨어를 여러 단계로 나누어 동시에 처리하는 기술이다.
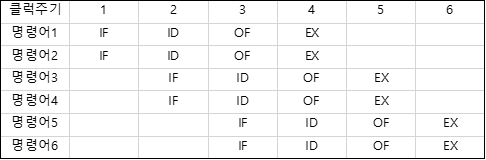
4-단계 파이프라인 기법을 예시로 들어보자면, 명령어 사이클은 총 4단계로 이루어진다.
1: 명령어 인출(Instruction Fetch) -> 2: 명령어 해독(Instruction Decoding) -> 3: 오퍼앤드 인출(Operand Fetch)단계 -> 4.실행(Execution)으로 이루어 진다.
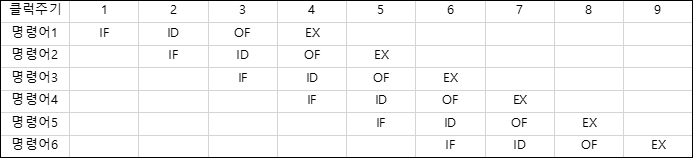
위 그림과 같이 1 클럭 주기 별로 나누어 작업을 수행한다.
슈퍼스칼라 기법
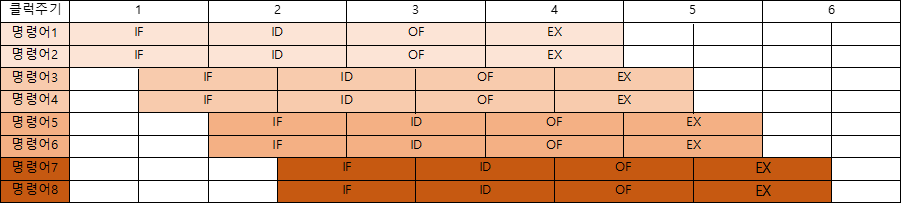
파이프라인을 처리할 수 있는 코어를 여러 개 구성함으로써, 복수의 명령어가 동시에 실행될 수 있도록 한다.
동시 처리가능한 명령어 개수에 따라서 N-Way 슈퍼스칼라라고 부른다.
슈퍼 파이프라인 기법
기존 파이프라인은 매 클럭마다 여러 명령어를 중복단계 없이 실행하지만, 슈퍼파이프라인은 하나의 클럭에 명령어가 중첩됨으로써, 시간의 병렬성을 높인 기법이다. 하나의 클럭에 명령어가 중첩됨으로써, 해저드 발생의 위험이 있다.

슈퍼 파이프라인 스칼라
여러개의 파이프를 둔 슈퍼스칼라를 한클럭에 명령어를 중첩시킨 기법으로써, 슈퍼파이프라인 기법을 듀얼코어 또는 그이상의 CPU를 사용하여 구현한 것이다.
위험
1. Data Hazard : 이전에 실행되어야할 명령의 정보가 필요한 경우가 발생하는 문제이다.
2. Control Hazard : PC(Program Counter)의 값이 갑작스러운 변화의 문제 제어문으로 명령어를 생략하고 넘어가게 할시 처리하는 명령어는 쓸모 없어짐
3. Structural Hazard : 명령어들이 같은 자원에 접근하려고 할 때 충돌의 문제
VLIW(Very Long Instruction Word)
명령어 처리기법중 하나로써, 명령어들을 종속성이 없는 것들 끼리 분류하여, 그걸 한번에 연결하여, 한번에 처리함으로써, 효율성을 높이는 방식이다!
이론적인 처리 속도는 정말 빠르다. 한번에 하나씩 처리하는 것보다는 당연히 여러개의 명령어를 한꺼번에 처리하는 것이 빠르다. VLIW 방식의 최대의 장점이다. 다양한 명령어 크기와 종속성 분석이 쉽지 않은 CISC 방식 명령어의 파이프라이닝보단 미리 종속성을 제거하고 크기가 일정하게 들어오는 VLIW 방식 명령어의 파이프라이닝이 더 간단할 수밖에 없다.
단점으로는 컴파일러 설계 난이도가 매우 높다. VLIW 방식 명령어 처리의 가장 큰 단점. VLIW 방식의 명령어 처리 기법을 효율적으로 쓰려면 애초에 Fetch되는 명령어의 크기가 일정하게 되어야 할 필요가 있다. 그러나 그렇게 하려면 컴파일러가 미리 바이너리 파일을 만들때 내부의 이진 코드의 크기를 일정하게 만들고 종속성이 최대한 줄어들도록 재배치해줘야 한다.
'CS > 운영체제 & 네트워크' 카테고리의 다른 글
| [Network] 데이터 전송 : 프로토콜과 OSI 7계층 및 Wireshark 패킷 분석 (0) | 2024.02.23 |
|---|---|
| [Network] 네트워크 개념과 구성 (0) | 2024.02.23 |
| [CS] 멀티 쓰레드 환경에서의 상호 배제(Mutex)와 데드락 (+ C#에서의 적용) (0) | 2022.08.03 |
| [Linux & 운영체제] 서버 속도가 느리다 (2) (0) | 2022.07.26 |
| [Linux & 운영체제] 서버 속도가 느리다 (0) | 2022.07.22 |







